
1.実用的な差分プライベートクラスタリング(2/2)まとめ
・プライベート・クラスタリング・アルゴリズムの前処理は通常と異なるので留意が必要
・今回のアルゴリズムは全てのデータポイントが収まるような半径の入力が必要
・半径が正確である必要はないが他の手法から事前にわかっている範囲が必要となる
2.差分プライベートクラスタリングの性能
以下、ai.googleblog.comより「Practical Differentially Private Clustering」の意訳です。元記事の投稿は2021年10月21日、Alisa ChangさんとPritish Kamathさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Annie Spratt on Unsplash
実験結果
このアルゴリズムをいくつかのベンチマークデータセットで評価し,(非プライベートな手法の)k-means++アルゴリズムや,利用可能な実装を持つ他のいくつかのアルゴリズム(diffprivlibおよびdp-clustering-icml17)と性能を比較しました。
以下のベンチマークデータセットを使用しています。
(i)64個のGaussian混合物からサンプリングされた100次元、10万個のデータポイントからなる合成データセット
(ii)手書き数字のデータセットであるMNISTでLeNetモデルを学習して得られたニューラル特徴表現
(iii)UC Irvineの文字認識に関するデータセット
(iv)UC IrvineのガスタービンのCOおよびNOx排出に関するデータセット
これらのベンチマークデータセットについて,ターゲットセンターの数(k)を変化させながら,正規化されたk-means損失(データポイントから最も近いセンターまでの平均2乗距離)を分析しました。考察した4つのデータセットのうち、3つのデータセットにおいて、今回説明したアルゴリズムは他のプライベート・アルゴリズムよりも低い損失を達成しました。
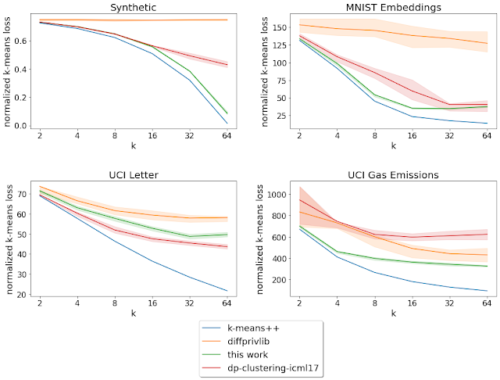
k = 「対象となるクラスタの数」を変化させた際の正規化損失(低い方が良い値です)。
実線は20回の実行結果の平均を示し、斜線領域は25-75パーセンタイルの範囲を示しています。
更に、検証済みラベル(既にグループ化されている)を持つデータセットについて、クラスタラベルの精度を分析しました。
これは、クラスタリングアルゴリズムによって発見された各クラスタにおける最も頻度の高い検証済みラベルを、そのクラスタ内のすべての点に割り当てることによって得られるラベリングの精度です。今回説明したアルゴリズムは、私達が検討した事前に指定された検証済みラベルを持つすべてのデータセットにおいて、他のプライベートアルゴリズムよりも優れた性能を示しました。
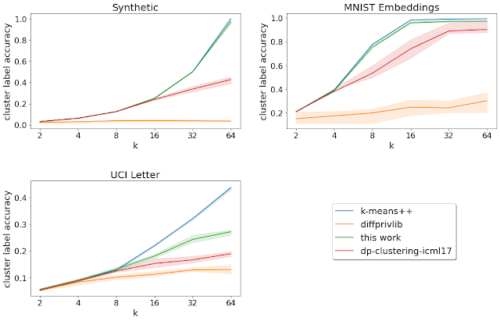
「k = 対象となるクラスタの数」を変化させたときのクラスタラベルの精度(大きいほど良い値です)曲線は20回の実行結果の平均を示します。斜線の領域は25-75パーセンタイルの範囲を示します。
制限事項と今後の研究の方向性
このライブラリやその他のライブラリをプライベート・クラスタリングに使用する際には、いくつかの制限事項があります。
(1)プライベート・クラスタリング・アルゴリズムを使用する前に行われる前処理(データポイントのセンタリングや異なる座標のリスケールなど)において、プライバシー損失を別途考慮することが重要です。将来的には、一般的に使用されている前処理方法と異なるプライベートな前処理方法をサポートしたり、必ずしも前処理されていないデータでもアルゴリズムの性能が向上するような変更を検討したいと考えています。
(2)このアルゴリズムでは、すべてのデータポイントがその半径の球内に収まるように、ユーザーが提供する半径が必要となります。この半径は、バケット平均に追加されるノイズの量を決定するために使用されます。これは、diffprivlibやdp-clustering-icml17とは異なり、データセットの境界に関する異なる概念(例えば、各座標の最小値と最大値)を取り込むことに注意が必要です。
実験評価のために、各データセットの関連する境界を非プライベートな手法で計算しました。しかし、実際にアルゴリズムを実行する際には、これらの境界は一般的なプライベートな手法で計算するか、データセットに関する事前知識がなくても提供される必要があります。(例えば、データの基調にある範囲を使用するなど)
ただし、今回説明したアルゴリズムの場合、提供された半径が正確である必要はないことに注意してください。提供された半径の外側にあるデータポイントは、その半径の球内にある最も近いポイントで置き換えられます。
結論
本研究では、差分プライバシーの枠組みの中で、代表点(クラスタセンター)を計算するための新しいアルゴリズムを提案しました。世界中で収集されたデータセットの量が増加している中、我々のオープンソースツールが、差分プライバシーを数学的に保証した上で、組織がデータセットに関する有意義な洞察を得て共有するのに役立つことを期待しています。
謝辞
Christoph Dibak, Badih Ghazi, Miguel Guevara, Sasha Kulankhina, Ravi Kumar, Pasin Manurangsi, Jane Shapiro, Daniel Simmons-Marengo, Yurii Sushko, and Mirac Vuslat Basaranの各氏に感謝します。
3.実用的な差分プライベートクラスタリング(2/2)関連リンク
1)ai.googleblog.com
Practical Differentially Private Clustering
2)proceedings.mlr.press
Locally Private k-Means in One Round
3)github.com
differential-privacy/learning/clustering/

