
1.Underspecification:検証データで測定した精度のみに頼る事の落とし穴(2/3)まとめ
・ImageNetで良好に機能する画像分類モデルは破損画像では不十分な性能しか出せない
・ImageNetで同等パフォーマンスを達成するモデル間でも破損画像に対する性能が異なる
・医療画像用など現実世界のモデルでも同様に堅牢性の観点から差が生じる事がわかった
2.Underspecificationの実例
以下、ai.googleblog.comより「How Underspecification Presents Challenges for Machine Learning」の意訳です。元記事の投稿は2021年10月18日、Alex D’AmourさんとKatherine Hellerさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Steven Lelham on Unsplash
コンピュータビジョンモデルにおける仕様不足
例として、仕様不足(Underspecification)と、コンピュータビジョンモデルの堅牢性との関係を考えてみましょう。
コンピュータビジョンの中心的な課題は、深層モデルは、人間が難しいとは思わないような「わずかに分布をシフトさせたデータ」に対する脆弱性に苦しむことが多いということです。
たとえば、ImageNetベンチマークで良好に機能する画像分類モデルは、標準のImageNetテストセットにモザイク処理やモーションブラーなどの良くある画像破損処理を適用させたImageNet-Cなどを使って性能を測定すると不十分な性能しか出せない事が知られています。
私たちの実験では、これらの破損に対するモデルの感度が標準パイプラインでは過小評価されていることを示しました。前述の戦略に従って、同じパイプラインと同じデータを使用して、50のResNet-50画像分類モデルを生成しました。
これらのモデルの唯一の違いは、トレーニングで使用されるランダムシードでした。標準のImageNet検証データセットで評価した場合、これらのモデルは実質的に同等のパフォーマンスを達成しました。
ただし、ImageNet-Cベンチマークのさまざまなテストセット(つまり、破損したデータ)でモデルを評価した場合の一部のパフォーマンス差異は、標準的なデータを使ったパフォーマンス差異よりも桁違いに異なりました。
このパターンは、はるかに大きなデータセットで事前トレーニングされた大規模モデル(たとえば、3億枚の画像JFT-300Mデータセットで事前トレーニングされたBiT-Lモデル)でも同じでした。これらのモデルでも、トレーニングの微調整段階でランダムシードを変化させると、同様の変化パターンが生成されました。
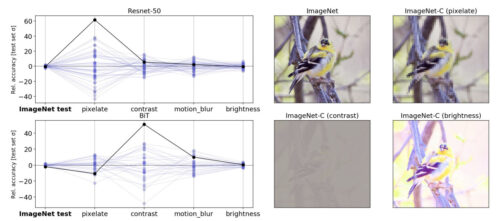
左:ランダムに初期化した同一のResNet-50モデルのImageNet-Cデータ(強く破損した画像)での精度のばらつき。各線は、破損していないテストデータと破損したデータ(モザイク化、コントラスト、モーションブラー、輝度)を使用した、分類タスクにおけるアンサンブル内の各モデルのパフォーマンスを表します。与えられた値は、アンサンブル平均からの精度の偏差であり、「クリーンな」ImageNetテストセットの精度の標準偏差によってスケールされます。黒い実線は、任意に選択したモデルのパフォーマンスを強調しています。あるテストのパフォーマンスが他のテストのパフォーマンスを適切に示していない可能性があることを示しています。
右:ImageNet-Cベンチマークの破損したバージョンを含む、標準のImageNetテストセットの画像の例
また、仕様不足は、深層学習モデルが大きな期待を示している医療画像用に構築された特殊用途のコンピュータービジョンモデルに実際的な影響を与える可能性があることも示しました。
本研究では、医療に応用する事を目的とした2つの研究パイプラインを検討しました。
1つは、網膜眼底画像から糖尿病性網膜症および糖尿病性黄斑浮腫を検出するモデルを構築する眼科パイプライン、もう1つは皮膚写真から一般的な皮膚疾患を認識するモデルを構築する皮膚科パイプラインです。
今回の実験ではパイプラインの検証データにランダムに選択したデータのみを使っています。次に、これらのパイプラインによって作成されたモデルを、現実世界で重要な観点に対してストレステストしました。
眼科パイプラインでは、さまざまなランダムシードでトレーニングされたモデルが、トレーニング中に遭遇しなかった新しいカメラタイプから取得された画像に適用されたときにどのように実行されるかをテストしました。
皮膚科パイプラインの場合、ストレステストは同様でしたが、推定される皮膚タイプが異なる患者(つまり、皮膚以外の要因による光による肌の色調変化と反応への評価)でした。
どちらの場合も、標準的な性能評価だけでは、これらの評価軸でモデルのパフォーマンスを完全に特定するには不十分であることがわかりました。
モデルの全体的なパフォーマンスはシード間で安定していましたが、眼科アプリケーションでは、トレーニングで使用されたランダムシードは、トレーニング時になかった新しいカメラタイプでは標準的な性能評価から予想されるよりも広いパフォーマンスの変動を引き起こしました。皮膚科アプリケーションでは、ランダムシードは皮膚タイプの異なるサブグループで同様のパフォーマンスの変動を引き起こしました。
3.Underspecification:検証データで測定した精度のみに頼る事の落とし穴(2/3)関連リンク
1)ai.googleblog.com
How Underspecification Presents Challenges for Machine Learning
2)arxiv.org
Underspecification Presents Challenges for Credibility in Modern Machine Learning
