
1.SimVLM:弱い教師を使ったシンプルな視覚言語モデル(2/2)まとめ
・SimVLMは非常に単純な構成であるにもかかわらず最先端のモデルを凌駕
・微調整せずともドイツ語で画像の説明文を作成するなどゼロショットが可能
・SimVLMは教師あり手法の品質に近いゼロショットキャプション品質に到達
2.SimVLMのゼロショット性能
以下、ai.googleblog.comより「SimVLM: Simple Visual Language Model Pre-training with Weak Supervision」の意訳です。元記事の投稿は2021年10月15日、Zirui WangさんとYuan Caoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by kevin laminto on Unsplash
ViTと同じセットアップに従って、3つの異なるサイズ(base:8600万パラメーター、large:3億0700万、およびhuge:6億3200万)でSimVLMモデルを評価します。結果をLXMERT、VL-T5、UNITER、OSCAR、Villa、SOHO、UNIMO、VinVLなどの強力な既存ベースラインと比較すると、SimVLMは、はるかに単純であるにもかかわらず、これらすべてのタスクで最先端のパフォーマンスを実現していることがわかります。
| VQA | NLVR2 | SNLI-VE | CoCo Caption | |||||||
| Model | test-dev | test-std | dev | test-P | dev | test | B@4 | M | C | S |
| LXMERT | 72.4 | 72.5 | 74.9 | 74.5 | – | – | – | – | – | – |
| VL-T5 | – | 70.3 | 74.6 | 73.6 | – | – | – | – | 116.5 | – |
| UNITER | 73.8 | 74 | 79.1 | 80 | 79.4 | 79.4 | – | – | – | – |
| OSCAR | 73.6 | 73.8 | 79.1 | 80.4 | – | – | 41.7 | 30.6 | 140 | 24.5 |
| Villa | 74.7 | 74.9 | 79.8 | 81.5 | 80.2 | 80 | – | – | – | – |
| SOHO | 73.3 | 73.5 | 76.4 | 77.3 | 85 | 85 | – | – | – | – |
| UNIMO | 75.1 | 75.3 | – | – | 81.1 | 80.6 | 39.6 | – | 127.7 | – |
| VinVL | 76.6 | 76.6 | 82.7 | 84 | – | – | 41 | 31.1 | 140.9 | 25.2 |
| SimVLM base | 77.9 | 78.1 | 81.7 | 81.8 | 84.2 | 84.2 | 39 | 32.9 | 134.8 | 24 |
| SimVLM large | 79.3 | 79.6 | 84.1 | 84.8 | 85.7 | 85.6 | 40.3 | 33.4 | 142.6 | 24.7 |
| SimVLM huge | 80 | 80.3 | 84.5 | 85.2 | 86.2 | 86.3 | 40.6 | 33.7 | 143.3 | 25.4 |
既存のベースラインモデルと比較した、6つの視覚言語ベンチマークのサブセットを使った評価結果
上記で使用されている指標(高いほど良い):BLEU-4(B@4)、METEOR(M)、CIDEr(C)、SPICE(S)。同様に、NoCapsとMulti30k En-Deの評価でも、最先端のパフォーマンスが示されています。
ゼロショットの一般化
SimVLMは、視覚的入力とテキスト入力の両方を使って大量のデータでトレーニングされているため、ゼロショットのクロスモダリティ転移を実行できるかどうかを試すのは興味深いことです。
この目的のために、画像の説明文、多言語の説明文、オープンエンドな質問のVQA、視覚-テキスト補完など、複数のタスクでモデルを調べます。
事前にトレーニングされたSimVLMを使用して、テキストデータのみを微調整するか、完全に微調整せずに、マルチモーダル入力用に直接デコードします。 次の図にいくつかの例を示します。 このモデルは、高品質の画像説明文だけでなく、ドイツ語の説明も生成でき、言語間およびモダリティ間の転移を同時に実現できることがわかります。

SimVLMのゼロショット一般化の例
(a)ゼロショット画像の説明文:テキストプロンプトとともに画像が与えられると、事前トレーニングされたモデルは微調整せずに画像内容を予測します。
(b)ドイツ語で書かれた画像説明文を使ったゼロショットクロスモダリティ転移:モデルは、ドイツ語の画像キャプションデータで微調整されていなくとも、ドイツ語でキャプションを生成します。
(c)生成VQA:モデルは、元のVQAデータセットの候補にない回答を生成できます。
(d)ゼロショットの視覚-テキスト補完:事前に訓練されたモデルは、画像の内容に基づいてテキストの説明を完成できます。
(e)ゼロショットオープンエンドVQA:モデルは、WITデータセットの事前トレーニングを実施した後、画像に関する質問に対する事実に基づく回答を提供します。 画像はNoCapsからのものであり、CC BY2.0ライセンスの下でOpenImagesデータセットから取得した画像です。
SimVLMのゼロショットパフォーマンスを定量化するために、事前トレーニングされたモデルを凍結し、COCOキャプションおよびNoCapsベンチマークでデコードしてから、教師ありモデルをベースラインとして比較します。教師あり微調整(中央の行)がなくても、SimVLMは教師あり手法の品質に近いゼロショットキャプション品質に到達できます。
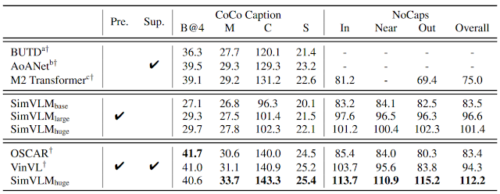
ゼロショット画像のキャプション結果。 「pre」はモデルが事前にトレーニングされており「Sup」はモデルがタスク固有の教師で微調整されていることを意味します。 NoCapsの場合、[In、Near、Out]は、それぞれドメイン内、ドメインに近い、ドメイン外を指します。 BUTD、AoANet、M2 Transformer、OSCAR、VinVLの結果を比較します。前述の指標(高いほど良い):BLEU-4(B@4)、METEOR(M)、CIDEr(C)、SPICE(S)。NoCapsの場合、CIDErの値が表示されています。
結論
VLP用のシンプルで効果的なフレームワークを提案します。
物体検出モデルとタスク固有の補助損失を使用した以前の研究とは異なり、私たちのモデルは、単一のプレフィックス言語モデルを目的として直接トレーニングされています。さまざまな視覚言語ベンチマークで、このアプローチは最先端のパフォーマンスを得るだけでなく、マルチモーダル理解タスクで興味をそそるゼロショット動作も示します。
謝辞
SimVLMの論文を作成してくれたJiahui Yu, Adams Yu, Zihang Dai, Yulia Tsvetkov、有益な議論をしてくれたHieu Pham, Chao Jia, Andrew Dai, Bowen Zhang, Zhifeng Chen, Ruoming Pang, Douglas Eck, Claire Cui, Yonghui Wu、データの準備に協力してくれたKrishna Srinivasan, Samira Daruki, Nan Du and Aashi Jain、実験の設定を支援してくれたJonathan Shen, Colin Raffel, Sharan Narang、およびこのプロジェクト全体をサポートしてくれたBrainチームの他のメンバーに感謝します。
3.SimVLM:弱い教師を使ったシンプルな視覚言語モデル(2/2)関連リンク
1)ai.googleblog.com
SimVLM: Simple Visual Language Model Pre-training with Weak Supervision
2)arxiv.org
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision

