
1.FedJAX:連合学習のシミュレーションをJAXで容易に実行(2/2)まとめ
・GPU、TPU 1 TensorCore、マルチコアTPUと2つのデータセットでFedJAXを評価
・TPUを使用するとfederated EMNIST-62は数分、Stack Overflowは約1時間で学習が完了
・参加するクライアントの数が多い場合、複数のTPUコアを使用すると実行時間が改善
2.FedJAXを使った評価
以下、ai.googleblog.comより「FedJAX: Federated Learning Simulation with JAX」の意訳です。元記事の投稿は2021年10月4日、Jae Hun RoさんとAnanda Theertha Sureshさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Yannis H on Unsplash
パフォーマンス評価
適応型フェデレーション平均(adaptive federated averaging)の標準FedJAX実装を2つのタスクで性能測定しました。
Federated EMNIST-62データセットを使った画像認識タスクとスタックオーバーフローデータセットを使った次の単語予測タスクです。
Federated EMNIST-62は、3400人のユーザーの手書き文字(全英数字62種)から構成される小さなデータセットです。一方、Stack Overflowデータセットははるかに大きく、数十万人のユーザーを対象としたStack Overflowフォーラム内の数百万の質問と回答で構成されています。
機械学習に特化したさまざまなハードウェアでパフォーマンスを測定しました。
Federated EMNIST-62の場合、GPU(NVIDIA V100)およびTPU(Google TPU v2の1 TensorCore)アクセラレーターで、各回ごとに10クライアントを使用して1500回モデルをトレーニングしました。
Stack Overflowの場合、各回ごとに50クライアントを使用して1500回のモデルを以下の条件でトレーニングしました。
・jax.jitを使用したGPU(NVIDIA V100)
・jax.jitのみを使用したTPU(Google TPU v2の1 TensorCore)
・jax.pmapを使用したマルチコアTPU(Google TPU v2の8 TensorCores)
以下のグラフでは、トレーニングラウンドの平均完了時間、テストデータを完全に評価する際にかかった時間、トレーニングと完全な評価の両方を含む全体的な実行にかかった時間を記録しています。
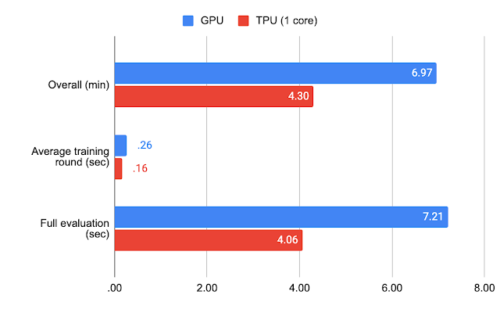
federated EMNIST-62のベンチマーク結果
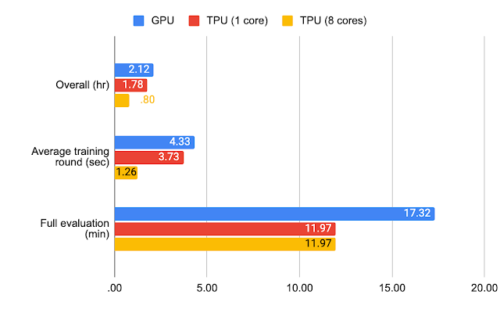
Stack Overflowのベンチマーク結果
標準のハイパーパラメータとTPUを使用すると、federated EMNIST-62の完全な実験は数分、Stack Overflowの場合は約1時間で完了できます。
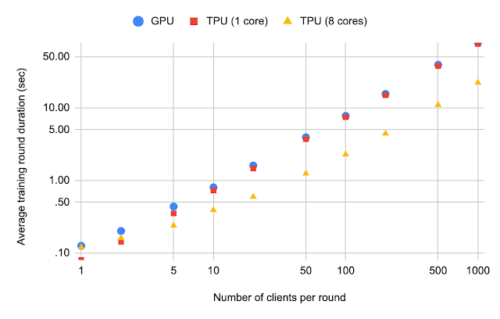
Stack Overflowの一回当た平均トレーニング時間とクライアント数の関係
また、一回あたりのクライアント数が増えるにつれて、Stack Overfloの平均トレーニングラウンド時間がどうなるかを評価しました。
図のTPU(8コア)とTPU(1コア)の平均トレーニングラウンド期間を比較してみてください。
各回ごとに参加するクライアントの数が多い場合、複数のTPUコアを使用すると、実行時間が大幅に改善されることは明らかです。(これは差分プライバシー学習などのアプリケーションに有用です)
結論と今後の研究
本投稿では、研究用の高速で使いやすい連合学習シミュレーションライブラリであるFedJAXを紹介しました。FedJAXが連合学習へのさらなる調査と関心を育むことを願っています。今後は、既存のアルゴリズム、集計メカニズム、データセット、モデルのコレクションを継続的に拡大する予定です。
チュートリアル用のColabノートブックをご覧になるか、FedJAXをご自身でお試しください。ライブラリとTensorflow Federatedなどのプラットフォームとの関係の詳細については、論文、README、またはFAQを参照してください。
謝辞
ライブラリと開発中のさまざまな議論に貢献してくれたKe WuとSai Praneeth Kamireddyに感謝します。また、Ehsan Amid, Theresa Breiner, Mingqing Chen, Fabio Costa, Roy Frostig, Zachary Garrett, Alex Ingerman, Satyen Kale, Rajiv Mathews, Lara Mcconnaughey, Brendan McMahan, Mehryar Mohri, Krzysztof Ostrowski, Max Rabinovich, Michael Riley, Vlad Schogol, Jane Shapiro, Gary Sivek, Luciana Toledo-Lopez, そして Michael Wunderのの有益なコメントと貢献にも感謝します。
3.連合学習のシミュレーションをJAXで容易に実行(2/2)関連リンク
1)ai.googleblog.com
FedJAX: Federated Learning Simulation with JAX
2)arxiv.org
FedJAX: Federated learning simulation with JAX
3)fedjax.readthedocs.io
FedJAX documentation
4)github.com
google / fedjax

