
1.教師あり学習を使って外れ値を発見する(3/3)まとめ
・異常検出は必ずしも完全に異なるか否かではなく一部に欠陥があるか否かで定義される
・回転予測と分布増強対照学習はテクスチャ異常検出では高い性能を発揮できない
・テクスチャ異常検出用にCutPasteデータ増強を使った新しい手法を開発した
2.CutPaste法を使ったデータ拡張
以下、ai.googleblog.comより「Discovering Anomalous Data with Self-Supervised Learning」の意訳です。元記事は2021年9月2日、Chun-Liang LiさんとKihyuk Sohnさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Yan Laurichesse on Unsplash
工業上の欠陥検出を行うためのテクスチャ異常検出
異常検出の多くの実際のアプリケーションでは、異常は、意味的に完全に異なる物体ではなく、局所的な欠陥によって定義されることがよくあります。(つまり、通常の物体と一部が通常ではない物体)。たとえば、壁面の異常の検出は、さまざまな種類の工業上の欠陥を検出するのに役立ちます。

セマンティック異常検出と欠陥検出(Defect Detection)の例
セマンティック異常検出では、通常値(inlier)と外れ値(outlier)は一般に異なります。(たとえば、一方は犬、もう一方は猫です)。欠陥検出では、通常値(inlier)と外れ値(outlier)は意味的に同じ物体ですが(たとえば、両方ともタイルです)、外れ値には局所的な異常があります。
回転予測と分布増強した対照学習を使用した特徴表現の学習は、セマンティック異常検出で最先端のパフォーマンスを実証しましたが、これらのアルゴリズムはテクスチャ異常検出ではうまく機能しません。代わりに、アプリケーションにより適したさまざまな特徴表現学習アルゴリズムを検討しました。
2番目の論文では、テクスチャ異常検出のための新しい自己教師あり学習アルゴリズムを提案します。全体的な異常検出は2段階フレームワークに従いますが、モデルが深い画像特徴表現を学習する最初の段階は、単純なCutPasteデータ増強によって画像が拡張されるかどうかを予測するように特別にトレーニングされています。
CutPaste増強の考え方は単純です。特定の画像は、一部分をランダムに切り取り、同じ画像の別の場所に貼り付けることによって水増しされます。通常の例とCutPasteで拡張された例を区別することを学ぶことで、特徴表現が画像の局所的な不規則性に敏感になるようになります。
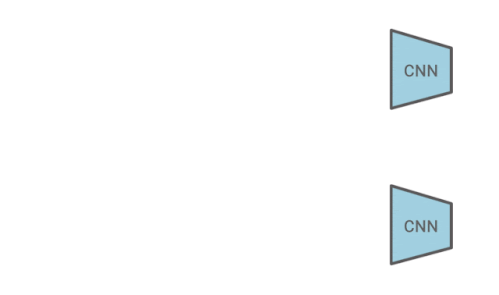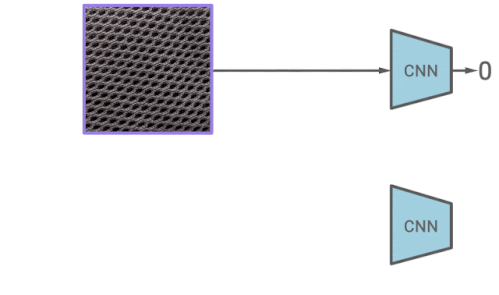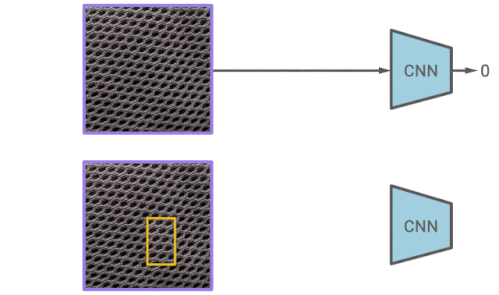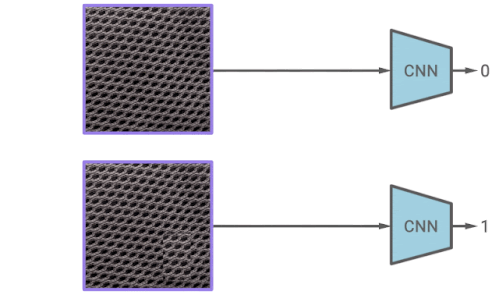
CutPasteによる増強を予測する特徴表現学習の図
例として、CutPaste拡張は局所的に断片を切り抜きし、それを同じ画像のランダムに選択された領域に貼り付けます。次に、元の画像とCutPasteによって増やした画像を区別するためにバイナリ分類器をトレーニングします。
上記のアプローチを評価するために、15の物体カテゴリを持つ実際の欠陥検出データセットであるMVTecを使用します。
| DOCC(Ruff et al., 2020) | U-Student(Bergmann et al., 2020) | Rotation Prediction | Contrastive (DA) | CutPaste |
| 87.9 | 92.5 | 86.3 | 86.5 | 95.2 |
MVTecベンチマークでの画像レベルの異常検出パフォーマンス(AUC)
画像レベルの異常検出に加えて、CutPasteメソッドを使用して、異常がどこにあるかを特定します。つまり、「断片レベル(patch-level)」の異常検出です。ガウス平滑化を使用したアップサンプリングを介して断片異常スコアを集計し、異常がどこにあるかを示すヒートマップでそれらを視覚化します。興味深いことに、これにより、異常の局所化が適切に改善されます。次の表は、局所化評価用の画素レベルのAUCを示しています。
| Autoencoder(Bergmann et al., 2019) | FCDD(Ruff et al., 2020) | Rotation Prediction | Contrastive (DA) | CutPaste |
| 86 | 92 | 93 | 90.4 | 96 |
MVTecベンチマークでの異なるアルゴリズム間の画素レベルの異常箇所検知パフォーマンス(AUC)の比較
結論
この研究では、新しい2段階深層1クラス分類フレームワークを紹介し、分類子と特徴表現学習を分離して、分類子がターゲットタスクである1クラス分類と一致できるようにすることの重要性を強調します。
さらに、このアプローチにより、さまざまな自己教師特徴表現学習手法のアプリケーションが可能になり、セマンティック異常検出からテクスチャ欠陥検出まで、視覚的な1クラス分類のさまざまなアプリケーションで最先端のパフォーマンスが得られます。トレーニングデータが本当にラベル付けされていないシナリオの下で、より現実的な異常検出方法を構築するための取り組みを拡大しています。
謝辞
Jinsung Yoon, Minho Jin, Tomas Pfisterを含む他の共著者からの貢献に感謝します。GitHubリポジトリでコードをリリースします。
3.教師あり学習を使って外れ値を発見する(3/3)関連リンク
1)ai.googleblog.com
Discovering Anomalous Data with Self-Supervised Learning
2)arxiv.org
Learning and Evaluating Representations for Deep One-class Classification
CutPaste: Self-Supervised Learning for Anomaly Detection and Localization
Self-Trained One-class Classification for Unsupervised Anomaly Detection
3)github.com
google-research / deep_representation_one_class

