
1.Agile Data Labeling:それが何であり、なぜそれが必要なのか?(2/3)まとめ
・データに注釈/ラベルを付ける作業は労力がかかるが第三者にアウトソーシングするのも困難
・会ったことのない完全に見知らぬ人に作業内容を一から説明して理解して貰う必要がある
・顧客や同僚からのフィードバックを重視するアジャイルなラベル付け体制を時代が求めている
2.データラベリングに関するアジャイルマニフェスト
以下、www.kdnuggets.comより「Agile Data Labeling: What it is and why you need it」の意訳です。元記事は2021年8月、Jennifer Prendkiさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Daria Nepriakhina on Unsplash
データに注釈/ラベルを付ける作業は困難です。
多くの機械学習科学者にとって、データに注釈を付けることは、彼らのワークロードの途方もなく大きな部分を占めています。また、データに自分で注釈を付けることはほとんどの人にとって楽しい作業ではありませんが、この注釈付け作業を第三者にアウトソーシングすることはさらに面倒な場合があります。
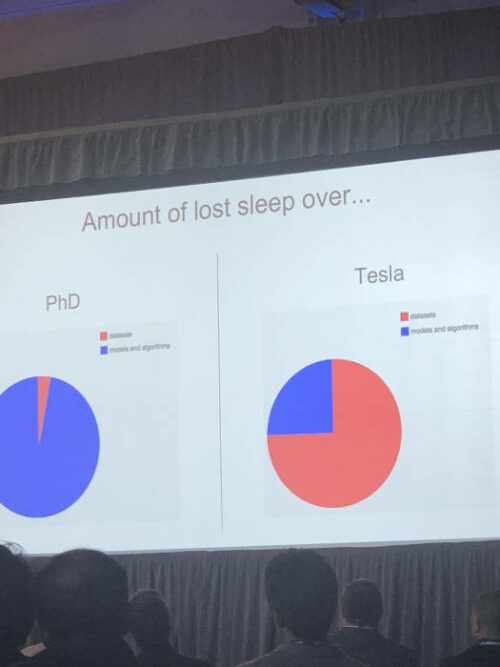
Train AI 2018でのAndrey Karpathyのスライドの1つ
ここでは、彼と彼のチームがテスラでデータの準備に費やした時間を説明しています。
想像してみてください。会ったことのない完全に見知らぬ人に作業内容を一から説明しなければなりません。
・どのようなツイートを有害なツイートと定義するのか?
・想定される検索キーワードとそれらの検索結果として望ましい結果はどのようなものなのか?
・画像内の広告写真に写っているを人を「人」と見なしてラベルづけして良いか?
などを、あなたが直接会話できない人々に対して行うのです。
何百人もの作業者はそれぞれ異なる意見や経歴を持っています。彼等があなたが達成しようとしている事が何かを全く知らないのに、あなたの指示をまったく同じように理解する事を保証しなければいけない状況を想像してみてください。
これが、ラベリングプロセスをアウトソーシングすると言う事です。

画像内に存在する広告内の人物に「人間」のラベルを付ける必要はありますか?
これらはアジャイルと何の関係があるのでしょうか?
まあ、まだあなたが感じ取れていなければ、ラベル付けに関するMLの科学者の間で高まる欲求不満が「私たちが物事をどのように成し遂げるかを再考するべき時が来た」というアイディアへの手がかりとなるかもしれません。
データラベリングに関するアジャイルマニフェストを宣言する時が来ました。
ソフトウェア開発のアジャイルマニフェストは、1つの基礎的概念である「反応性(reactivity)」に要約されます。そこでは、厳格なアプローチは機能しないと述べています。代わりに、ソフトウェアエンジニアは、顧客や同僚からのフィードバックに依存する必要があります。
彼らは、最終的な目標を確実に達成できるように、自分の過ちに適応し、そこから学ぶ準備ができている必要があります。「フィードバック」と、その「フィードバックに対して反応できない事」が、チームがアウトソーシングを恐れる理由であるため、これは興味深いことです。これが、ラベル付けタスクにばかげた時間がかかり、企業に数百万ドルの費用がかかることが多い主な理由です。
データラベリングのアジャイルマニフェストを成功させるには、同じ反応性の原則から始める必要があります。これは、データラベリング会社の説明には驚くほど欠けています。トレーニングデータの準備を成功させるには、協力、フィードバック、および規律が必要です。
データラベリングのアジャイルマニフェスト
複数の手法を戦略的に組み合わせる > 標準的なパラダイムに従う
マーケットの強みを利用する > 単一のラベル付けパートナーに頼る
反復的アプローチを取る > 一回のステップで終わらせようと試みる
ラベルの品質を重視する > 大規模データセットを前提とする
3.Agile Data Labeling:それが何であり、なぜそれが必要なのか?(2/3)関連リンク
1)www.kdnuggets.com
Agile Data Labeling: What it is and why you need it
2)agilemanifesto.org
アジャイルソフトウェア開発宣言

訳注:昔、必要に迫られてあるデータセットのchopsticks(箸)のラベルが付いた画像を全て目視で確認した事があるのですが、正確にラベル付けできているケースの方が少ない事がありました。箸の文化圏の人が作業に関わっていないのか、箸と串の違いがついておらず、場合によってはラーメンの中に差し入れられていて先端が見えていないレンゲなどもchopsticksとラベル付けされていて驚いた事があります。かなりの時間をかけて全部をチェックして修正ラベルとして送付した事があるのですが、ちゃんと修正を取り入れてくれたのかどうかも良くわかりませんでした。
これがもし、プログラムのプルリクエストであったら放置されるような事はあまりないと思うのですが、データやラベルは完了後も維持管理に手間がかかる事は見過ごされていて明確な管理者がいないのかな、と感じた事を覚えています。有名なデータセットでも一部がnot foundで取得できない状態で放置されている事はありますものね。
もし、フィードバックに迅速に反応する姿勢が重視されるアジャイルな体制になればこういった事は無くなるのかもしれませんが、ラベル付けだけ切り出してアジャイル化しても難しいだろうな、とも思います。
「データセットを固定して、様々なモデルでその固定したデータセットに対して性能を計測して優劣を決める」と言うやり方も改めないと「データセットに頻繁に変更が発生しては困る」という話になってしまうはずなので。
現実世界が漂流(ドリフト)していくのに、データセットを固定して性能を計測するやり方が正しいのかと言うと、おそらくそこには改善の余地があり、A/Bテストのやり方の再検討などをしていく必要も出て来るのかな、とは思います。