
1.人工内耳に高度な音声強調技術を適用(2/2)まとめ
・刺激パルスを固定時間間隔にするために細かい時間的構造を犠牲にしている事で品質が低下
・パルス生成処理を音の波形のピークに合わせるようにすると明瞭さが増すように聞こえる
・課題はあるが音声の微細な時間構造を維持することに価値がありそうだと言う事が判明
2.Conv-TasNetとは?
以下、ai.googleblog.comより「Applying Advanced Speech Enhancement in Cochlear Implants」の意訳です。元記事は2021年7月23日、Samuel J. YangさんとDick Lyonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Joeyy Lee on Unsplash
Conv-TasNet音声強調モデル
ノイズや音楽などの非音声を抑制する音声強調モジュールを実装するために、さまざまな種類の音を分離できるConv-TasNetモデルを使用します。
まず、生のオーディオ波形が変換され、ニューラルネットワークで使用できる形式に処理されます。このモデルは、学習する分析変換器を使用して、入力オーディオを短い2.5ミリ秒のフレームに変換し、音の分離に最適化された特徴を生成します。
次に、ネットワークはこれらの特徴から2つの「マスク」を生成します。1つは音声用のマスク、もう1つはノイズ用のマスクです。これらのマスクは、各特徴が音声またはノイズのいずれかに対応する度合を指示します。分離された音声とノイズにマスクを分析対象の特徴と共に掛け合わせ、合成変換を行って短いオーディオに戻し、結果として出来た短いフレームをつなぎ合わせ、オーディオとして再構築します。
最後のステップとして、音声とノイズの推定値は混合整合性レイヤー(mixture consistency layer)によって処理されます。混合整合性レイヤーは、元の入力混合波形と合わせるようにすることで、推定波形の品質を向上させます。
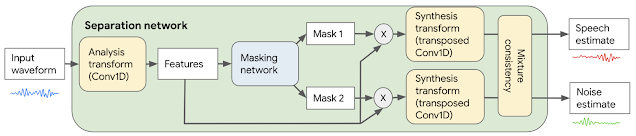
Conv-TasNetに基づく音声強調システムの概要図
このモデルは、独創的で低遅延です。入力オーディオの2.5ミリ秒ごとに、モデルは分離された音声とノイズの推定値を生成するため、リアルタイムで使用できます。ハッカソンでは、将来のハードウェアで計算能力を向上させることで何が可能になるかを示すために、290万個のパラメーターを持つモデルの亜種を採用する事にしました。このモデルはサイズが大きすぎて、現在のCIに実際に実装することはできませんが、将来、より高性能なハードウェアでどのようなパフォーマンスが可能になるかを示しています。
結果を聞く
モデルと全体的なソリューションを最適化する際に、ハッカソンが提供するボコーダー(電気パルスの時間間隔を固定する必要があります)を使用して、CIユーザーが知覚する可能性のあるものをシミュレートするオーディオを生成しました。次に、典型的な聴覚ユーザーとしてA-Bリスニングテストをブラインドテストとして実施しました。
以下のボコーダーシミュレーションを聞くと、入力音にバックグラウンドノイズがあまり含まれていない場合、再構成された音の音声(エレクトロドグラムを処理するボコーダーから)はかなり理解できますが、音声の明瞭さを改善する余地はまだあります。
私たちの提出物は、スピーチ・イン・ノイズのカテゴリーでうまく機能し、全体で2位を獲得しました。
CIユーザーがオーディオから知覚する可能性のある音声のボコーダーシミュレーション。
バックグラウンドノイズとノイズ抑制が適用済みで固定された時間間隔のエレクトロドグラムを使用
品質のボトルネックは、刺激パルスを固定時間間隔にするために音声の細かい時間的構造を犠牲にしている事です。パルス生成処理をフィルタリングされた音の波形のピークに合わせるように変更すると、インプラント刺激パターンで従来表現されているよりも、音のピッチと構造に関するより多くの情報を捕捉できます。
上記と同じボコーダーを使用しますが、刺激パルスを音の波形のピークに同期させるように変更した処理を用いたエレクトロドグラムでのボコーダーシミュレーション
この2番目のボコーダー出力は、実際のCIユーザーにどのように聞こえるかについて楽観的すぎることに注意することが重要です。たとえば、ここで使用されている単純なボコーダーは、蝸牛内の電流の広がりが刺激をぼかす方法をモデル化していないため、さまざまな周波数を解決するのが難しくなります。しかし、これは少なくとも、微細な時間構造を維持することに価値があり、エレクトロドグラム自体がボトルネックではないことを示唆しています。
理想的には、すべての処理アプローチは、ボコーダーを使ったシミュレーションに依存するのではなく、CIに直接実装されたエレクトロドグラムを使用して、幅広いCIユーザーによって評価される事です。
結論と協力の呼びかけ
私達は、この経験を2つの主要な方向でフォローアップすることを計画しています。
まず、補聴器、転記、振動触覚感覚置換(vibrotactile sensory substitution)など、他の聴覚アクセシビリティ入力装置へのノイズ抑制の適用を検討する予定です。
次に、人工内耳のエレクトロドグラムパターンの作成について更に詳しく研究します。業界で標準的な通常のCIS(連続インターリーブサンプリング)パターンに対応していない細かい時間構造を利用してこれを行います。
Louizou氏によれば「受信しているスペクトル情報が限られているのに、片方の聴力のみ低下している一部の患者がどうやってうまく適応できているのかは謎のままです」。したがって、細かい時間構造を使用することは、CIのユーザ体験の向上を達成するための重要なステップになる可能性があります。
Googleは、障害を持つ人々と一緒に、そして障害を持つ人々のためにテクノロジーを構築することに取り組んでいます。人工内耳(または補聴器)の最先端技術を改善するために協力することに興味がある場合は、ci-collaboratorsのgooglegroupsまでご連絡ください。
謝辞
この機会を与えてくれ、私たちと協力してくれたCochlear Impactハッカソンの主催者に感謝します。Googleの参加チームは、Samuel J. Yang, Scott Wisdom, Pascal Getreuer, Chet Gnegy, Mihajlo Velimirović, Sagar Savla, and Richard F. Lyonで、Dan EllisとManoj Plakalの指導を受けています。
3.人工内耳に高度な音声強調技術を適用(2/2)関連リンク
1)ai.googleblog.com
Applying Advanced Speech Enhancement in Cochlear Implants
2)github.com
google-research/cochlear_implant/
3)cihackathon.com
CI Hackathon
4)groups.google.com
ci-collaborators

