
1.人工内耳に高度な音声強調技術を適用(1/2)まとめ
・人工内耳(CI)は外部サウンドプロセッサを介して聴覚神経を電気的に刺激する電子デバイス
・補聴器は音を増幅させるだけだがCIは音声を電気刺激として感じさせる事が出来る
・CIでノイズのあるスピーチのノイズ抑制処理を行うと聞き取りやすさと明瞭さが劇的に向上
2.人工内耳とは?
以下、ai.googleblog.comより「Applying Advanced Speech Enhancement in Cochlear Implants」の意訳です。元記事は2021年7月23日、Samuel J. YangさんとDick Lyonさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Joeyy Lee on Unsplash
聴覚に困難を抱える、または難聴の世界の約4億6600万人にとって、ユーザ補助サービスを気軽に利用できない事は、人々の間で日常的に行われる会話に参加する上で障壁となる可能性があります。
補聴器はこれを軽減するのに役立ちますが、単に音を増幅するだけでは多くの人にとって不十分です。利用可能な他の選択肢の1つは、人工内耳(CI:Cochlear Implant)です。これは、蝸牛と呼ばれる内耳の一部に外科的に挿入され、外部サウンドプロセッサを介して聴覚神経を電気的に刺激する電子デバイスです。これらの人工内耳を装着した多くの人は、これらの電気刺激を可聴音声として解釈することを学ぶことができますが、リスニングが必要な場面は非常に多様であり、騒がしい環境では特に困難です。
最新の人工内耳は、外部のサウンドプロセッサによって計算される拍動性信号(つまり、離散刺激パルス)で電極を駆動します。CI関連分野が依然として直面している主な課題は、音声を最適に処理する方法です。
これは、ユーザーが理解しやすい方法で音声を最適に処理する事であり、つまりは音を電極上でパルス信号に変換する方法です。
最近、この問題の進展を刺激するために、産業界と学界の科学者がCIハッカソン(設計者や開発者が集まってプログラムなどの開発作業を短期集中で競い合うイベント)を組織して、この問題に対する解法案をより幅広く募りました。
本投稿では、音声強調プリプロセッサ(具体的にはノイズ抑制器)をCIのプロセッサへの入力に使用して、ノイズの多い環境下で音声に対するユーザーの理解を高めることができることを示す探索的研究を共有します。
また、CIハッカソンに参加して本作業をどのように構築したか、および本作業をどのように開発し続けるかについても説明します。
ノイズ抑制によるCIの改善
2019年、CIプロセッサでノイズ抑制をする利点が小規模な内部プロジェクトにより実証されました。このプロジェクトでは、参加者は60の事前に録音および処理されたオーディオサンプルを聴き、聴き心地によってランク付けしました。CIユーザーは、電気パルスを生成するためのデバイスの従来の戦略を使用してオーディオを聴きました。
Audio with background noise
Audio with background noise + noise suppression
Kenny MacCarthyによる「IMG_0991.MOV」のバックグラウンドオーディオクリップ(CC-BY2.0ライセンス)
以下の図に示すように、ノイズのあるスピーチ(最も白っぽいバー)がノイズ抑制で処理されると、通常、リスニングの聞き取りやすさ(listening comfort)と明瞭さ(intelligibility)の両方が、時には劇的に向上しました。
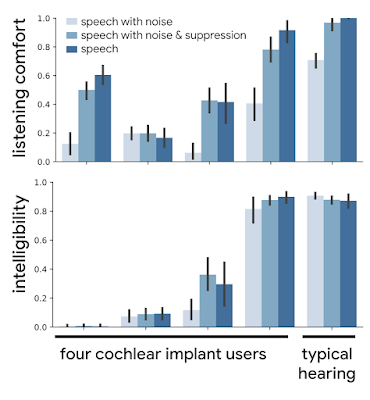
初期のCIユーザーに関する調査研究は、リスニングの快適さを改善しました。ここでは「非常に悪い」(0.0)から「OK」(0.5)、「非常に良い」(1.0)まで定性的にスコア付けされました。更に、ノイズの多い音声サンプルにノイズ抑制器が適用された際の音声明瞭性(つまり、正しく転写された文の単語の割合)も改善されました。
CIハッカソンでは、このプロジェクトに基づいて構築し、ノイズ抑制器の使用を引き続き活用しながら、パルスを計算するアプローチも検討しました。
処理アプローチの概要
ハッカソンでは、16個の電極を備えたCIを検討しました。
私たちのアプローチは、蝸牛内の電極の位置に対応して、オーディオを16の重なり合う周波数帯域に分解します。次に、音のダイナミックレンジは、電極が表すと予想される範囲よりも数桁広いため、「チャネルごとのエネルギー正規化」(PCEN:Per-Channel Energy Normalization)を適用して、信号のダイナミックレンジを積極的に圧縮します。最後に、範囲圧縮された信号を使用して、エレクトロドグラム(つまり、CIが電極に陳列するもの)を作成します。
更に、ハッカソンでは、音楽を含む複数のオーディオカテゴリで成果物を提出して評価される必要がありました。音楽はCIユーザーが楽しむために重要な要素ですが、音としては悪名高いほど取り扱いが難しいのです。
例えば、音声を強調するネットワークは、音声を聞き取りやすくするために、非音声を抑制するようにトレーニングされています。非音声にはノイズと音楽の両方が含まれるため、会話の邪魔にならない環境音楽が抑制される事を回避するために追加の対策を講じる必要がありました。(一般に、特定の状況では音楽を抑制する事が一部のユーザーに好まれる場合があることに注意してください)
これを行うために、「元の音楽」と「ノイズ抑制処理が行われた音楽」をミックスし、音楽がノイズ抑制処理後も十分に聞こえ続けるようにしました。
ミックスされた元の音楽の割合を0%から40%までリアルタイムで変化させました。(すべての入力が音声として推定される場合は0%、入力の多くが非音声として推定される場合は40%)入力が音声か非音声かは、音声を約1秒毎に区切ってオープンソースのYAMNet分類器で推定させた結果に基づいています。
3.人工内耳に高度な音声強調技術を適用(1/2)関連リンク
1)ai.googleblog.com
Applying Advanced Speech Enhancement in Cochlear Implants
2)github.com
google-research/cochlear_implant/
3)cihackathon.com
CI Hackathon
4)groups.google.com
ci-collaborators

