
1.Triton:ニューラルネットワーク用のGPUプログラミングを楽にする新言語まとめ
・TritonはcutlassやTVMのようなGPUに直接命令を出すGPUプログラミングを楽にする新言語
・Tritonを使用すると比較的少ない労力でハードウェアの最高パフォーマンスを引き出す事が可能
・OpenAIの研究者は同等のPyTorch実装よりも最大2倍効率的なカーネルを作成できている
2.GPUプログラミングを楽にするTritonとは?
以下、openai.comより「Introducing Triton: Open-Source GPU Programming for Neural Networks」の意訳です。元記事は2021年7月28日、Philippe Tilletさんによる投稿です。
正直に書くと、タイトルを読んだ瞬間には「今更、新しいプログラミング言語だと!?」と思ってスルーしそうになったのですが、現時点ではTritonはPython等のスクリプト言語を代替しようとするものではなく「今の機材でこれ以上のパフォーマンスを出すにはGPUを直で叩いてチューニングしていくしかない」といった状況になった時にCUDAを直接扱うよりは全然楽ですよ、という特化型のコンパイラに近い位置付けと思います。
ですので、脚注にもあったのですが、NVIDIA/cutlassやApache/TVMなどのGPUに直接命令を出すようなGPUプログラミングを楽にするためのツールであって、これらのキーワードを検索していて本ページにたどり着いた方は、Tritonも選択肢に入れると良いかと思います。なお、Version1.0時点ではNVIDIAのGPUに限定されていますが、将来的にはAMDのGPUへの対応も見据えているようです。fast.aiのJeremy Howardさんも褒めていたので性能やコンセプトが素晴らしい事は間違いないです。
Tritonはギリシャ神話のPoseidonの子であり半人半魚の海神との事でアイキャッチ画像はTritonの噴水でクレジットはPhoto by iam_os on Unsplash
Pythonに似たオープンソースのプログラミング言語であるTriton1.0をリリースします。Tritonを使うと、NVIDIAのCUDAを使った経験がない研究者でも、ほとんどの場合、専門家が作成できるものと同等の非常に効率的なGPUコードを記述できます。
Tritonを使用すると、比較的少ない労力でハードウェアの最高のパフォーマンスを引き出す事ができます。例えば、25行未満のコードでcuBLASのパフォーマンスに一致するFP16行列乗算カーネルを作成する事ができます。これは多くのGPUプログラマーが実行できないことです。
私たちの研究者はすでにTritonを使用して、同等のPyTorch実装よりも最大2倍効率的なカーネルを作成しており、コミュニティと協力してGPUプログラミングを誰もが利用しやすくすることに興奮しています。
ディープラーニングの分野における新しい研究アイデアは、通常、ネイティブなフレームワーク操作の組み合わせを使用して実装されます。このアプローチは便利ですが、多くの場合、多くの一時テンソルの作成(および/または移動)を必要とし、大規模なニューラルネットワークのパフォーマンスを損なう可能性があります。
これらの問題は、特殊なGPUカーネルを作成することで軽減できますが、GPUプログラミングは非常に複雑であるため、これを行うのは驚くほど難しい場合があります。
また、このプロセスを簡単にするために最近さまざまなシステムが登場しましたが、それらは冗長すぎるか、柔軟性に欠けるか、手動で作成した比較対象コードよりも著しく遅いコードを生成することがわかりました。 これにより、最新のプログラミング言語およびコンパイラであるTritonを拡張および改善することになりました。Tritonの元の開発者は現在OpenAIで働いています。
GPUプログラミングの難しさ
最新のGPUのアーキテクチャは、DRAM、SRAM、ALUの3つの主要コンポーネントに大別できます。これらは、CUDAコードを最適化する際にそれぞれ考慮する必要があります。
(1)最新の広いバス幅を持つメモリインターフェイスを活用するためには、DRAMからメモリ転送する際に大規模なトランザクションに統合する必要があります。
(2)データは、再利用する前に手動でSRAMに格納し、共有メモリバンクの競合を最小限に抑えるように取得時に競合管理をする必要があります。
(3)計算は分割し、慎重にスケジュール化する必要があります。
ストリーミングマルチプロセッサ(SM)全体および内部の両方で、命令/スレッドレベルの並列処理を促進し、特別な目的のALU(テンソルコアなど)を活用する必要があります。
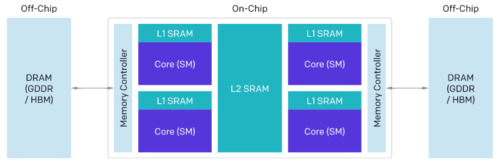
GPUの基本アーキテクチャ
長年の経験を持つベテランのCUDAプログラマーにとってさえ、これらすべての要因について論理設計することは難しい場合があります。Tritonの目的は、これらの最適化を完全に自動化することです。これにより、開発者は並列コードの高レベルのロジックに集中できます。Tritonは広く適用できることを目指しているため、SM間で作業を自動的にスケジュールすることはありません。いくつかの重要なアルゴリズムの考慮事項(タイリング(tiling)、SM間同期(inter-SM synchronization)など)は開発者の裁量に任されています。
| CUDA | TRITON | |
| Memory Coalescing | Manual | Automatic |
| Shared Memory Management | Manual | Automatic |
| Scheduling (Within SMs) | Manual | Automatic |
| Scheduling (Across SMs) | Manual | Manual |
CUDAとTritonのコンパイラの最適化対象の比較
プログラミングモデル
現在利用可能なすべての特定領域向け固有言語とJITコンパイラの中で、TritonはおそらくNumbaに最も似ています。カーネルは装飾されたPython関数として定義され、いわゆるインスタンスのグリッド上で異なるprogram_idと同時に起動されます。ただし、以下のコード断片に示すように、類似点はそこで終わります。
Tritonは「単一命令、複数スレッド(SIMT:Single Instruction, Multiple Thread)」実行モデルではなく、ブロック(次元が2の累乗である小さな配列)に対する操作を介してインスタンス内の並列処理を扱います。
そうすることで、Tritonは、CUDAスレッドブロック内の同時実行性に関連するすべての問題(メモリの合体、共有メモリの同期/競合、テンソルコアスケジューリングなど)を効果的に抽象化します。
Numbaのコード例
BLOCK = 512
# This is a GPU kernel in Numba.
# Different instances of this
# function may run in parallel.
@jit
def add(X, Y, Z, N):
# In Numba/CUDA, each kernel
# instance itself uses an SIMT execution
# model, where instructions are executed in
# parallel for different values of threadIdx
tid = threadIdx.x
bid = blockIdx.x
# scalar index
idx = bid * BLOCK + tid
if id < N:
# There is no pointer in Numba.
# Z,X,Y are dense tensors
Z[idx] = X[idx] + Y[idx]
...
grid = (ceil_div(N, BLOCK),)
block = (BLOCK,)
add[grid, block](x, y, z, x.shape[0])Tritonのコード例
BLOCK = 512
# This is a GPU kernel in Triton.
# Different instances of this
# function may run in parallel.
@jit
def add(X, Y, Z, N):
# In Triton, each kernel instance
# executes block operations on a
# single thread: there is no construct
# analogous to threadIdx
pid = program_id(0)
# block of indices
idx = pid * BLOCK + arange(BLOCK)
mask = idx < N
# Triton uses pointer arithmetics
# rather than indexing operators
x = load(X + idx, mask=mask)
y = load(Y + idx, mask=mask)
store(Z + idx, x + y, mask=mask)
...
grid = (ceil_div(N, BLOCK),)
# no thread-block
add[grid](x, y, z, x.shape[0])これは、驚異的並列問題(つまり、全要素単位)の計算には特に役立ちませんが、より複雑なGPUプログラムの開発を大幅に簡素化できます。
たとえば、各インスタンスが指定された入力テンソル\(x \in \mathbb{R}^{M \times N}\)の異なる行を正規化する融合ソフトマックスカーネル(下図)の場合を考えてみます。
この並列化戦略の標準CUDA実装は、XXの同じ行を同時に削減するため、スレッド間の明示的な同期が必要になるため、作成が難しい場合があります。
この複雑さのほとんどは、各カーネルインスタンスが対象の行をロードし、NumPyのようなプリミティブを使用して順次正規化するTritonで解消されます。
Tritonの融合ソフトマックスの例
import triton
import triton.language as tl
@triton.jit
def softmax(Y, stride_ym, stride_yn, X, stride_xm, stride_xn, M, N):
# row index
m = tl.program_id(0)
# col indices
# this specific kernel only works for matrices that
# have less than BLOCK_SIZE columns
BLOCK_SIZE = 1024
n = tl.arange(0, BLOCK_SIZE)
# the memory address of all the elements
# that we want to load can be computed as follows
X = X + m * stride_xm + n * stride_xn
# load input data; pad out-of-bounds elements with 0
x = tl.load(X, mask=n < N, other=-float('inf'))
# compute numerically-stable softmax
z = x - tl.max(x, axis=0)
num = tl.exp(z)
denom = tl.sum(num, axis=0)
y = num / denom
# write back to Y
Y = Y + m * stride_ym + n * stride_yn
tl.store(Y, y, mask=n < N)
import torch
# Allocate input/output tensors
X = torch.normal(0, 1, size=(583, 931), device='cuda')
Y = torch.empty_like(X)
# SPMD launch grid
grid = (X.shape[0], )
# enqueue GPU kernel
softmax[grid](Y, Y.stride(0), Y.stride(1),
X, X.stride(0), X.stride(1),
X.shape[0] , X.shape[1])Triton JITは、XとYをテンソルではなくポインタとして扱うことに注意してください。より複雑なデータ構造(ブロックスパーステンソルなど)に対処するには、メモリアクセスを低レベルで制御できるように維持することが重要であると感じました。
重要なのは、softmaxのこの特定の実装により、正規化プロセス全体を通じてXXの行がSRAMに保持されるため、該当する場合はデータの再利用が最大化されます(~< 32K列)。
これは、PyTorchの内部CUDAコードとは異なります。PyTorchのコードでは、一時メモリを使用するので、より汎用的になりますが、大幅に遅くなります。以下を参照)
ここで重要なのは、Tritonが本質的に優れているということではなく、汎用ライブラリよりもはるかに高速な特殊なカーネルの開発を簡素化出来るということです。
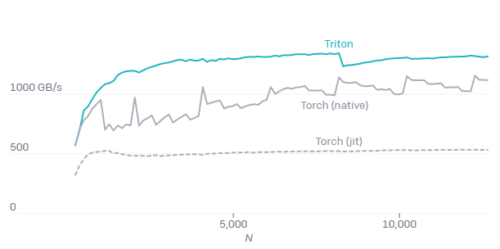
M = 4096の場合の融合ソフトマックスのA100パフォーマンス
Torch(v1.9)JITのパフォーマンスが低いことは、高レベルのテンソル操作から自動でCUDAコードを生成する事難しさを浮き彫りにします。
@torch.jit.script
def softmax(x):
x_max = x.max(dim=1)[0]
z = x - x_max[:, None]
numerator = torch.exp(x)
denominator = numerator.sum(dim=1)
return numerator / denominator[:, None]ソフトマックスとtorch JITの融合
行列の乗算
要素毎の演算や削減ができる融合カーネルを記述できることは重要ですが、ニューラルネットワークでの行列乗算タスクの卓越性を考えると十分ではありません。結局のところ、Tritonはそれらにも非常にうまく機能し、わずか25行のPythonコードで最高のパフォーマンスを達成します。一方、CUDAで同様の何かを実装すると、より多くの労力がかかり、パフォーマンスが低下する可能性さえあります。
Tritonでの行列乗算
@triton.jit
def matmul(A, B, C, M, N, K, stride_am, stride_ak,
stride_bk, stride_bn, stride_cm, stride_cn,
**META):
# extract metaparameters
BLOCK_M, GROUP_M = META['BLOCK_M'], META['GROUP_M']
BLOCK_N = META['BLOCK_N']
BLOCK_K = META['BLOCK_K']
# programs are grouped together to improve L2 hit rate
_pid_m = tl.program_id(0)
_pid_n = tl.program_id(1)
pid_m = _pid_m // GROUP_M
pid_n = (_pid_n * GROUP_M) + (_pid_m % GROUP_M)
# rm (resp. rn) denotes a range of indices
# for rows (resp. col) of C
rm = pid_m * BLOCK_M + tl.arange(0, BLOCK_M)
rn = pid_n * BLOCK_N + tl.arange(0, BLOCK_N)
# rk denotes a range of indices for columns
# (resp. rows) of A (resp. B)
rk = tl.arange(0, BLOCK_K)
# the memory addresses of elements in the first block of
# A and B can be computed using numpy-style broadcasting
A = A + (rm[:, None] * stride_am + rk[None, :] * stride_ak)
B = B + (rk [:, None] * stride_bk + rn[None, :] * stride_bn)
# initialize and iteratively update accumulator
acc = tl.zeros((BLOCK_M, BLOCK_N), dtype=tl.float32)
for k in range(K, 0, -BLOCK_K):
a = tl.load(A)
b = tl.load(B)
# block level matrix multiplication
acc += tl.dot(a, b)
# increment pointers so that the next blocks of A and B
# are loaded during the next iteration
A += BLOCK_K * stride_ak
B += BLOCK_K * stride_bk
# fuse leaky ReLU if desired
# acc = tl.where(acc >= 0, acc, alpha * acc)
# write back result
C = C + (rm[:, None] * stride_cm + rn[None, :] * stride_cn)
mask = (rm[:, None] < M) & (rn[None, :] < N)
tl.store(C, acc, mask=mask)手動で設計した行列乗算カーネルの重要な利点の1つは、入力(スライスなど)と出力(Leaky ReLUなど)の融合変換に対応するように、必要に応じてカスタマイズできることです。
Tritonのようなシステムがなければ、行列乗算カーネルの重要な変更は、GPUプログラミングの専門知識がない開発者にとっては手の届かないものになります。
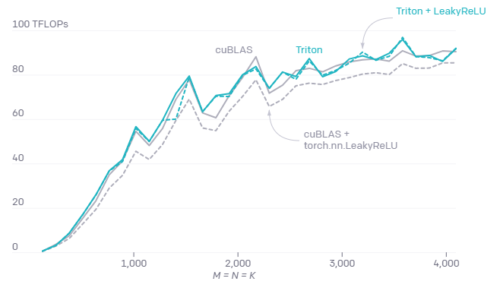
BLOCK_M, BLOCK_N, BLOCK_K, GROUP_Mの適切に調整された行列乗算をV100テンソルコア上で行ったパフォーマンス比較
高レベルのシステムアーキテクチャ
Tritonの優れたパフォーマンスは、Triton-IRを中心としたモジュラーシステムアーキテクチャに由来します。これは、コンパイラ基盤のベースであり、多次元ブロック値の中間表現であり、基本的なオブジェクト操作が可能な第一級オブジェクト(first-class citizens)です。
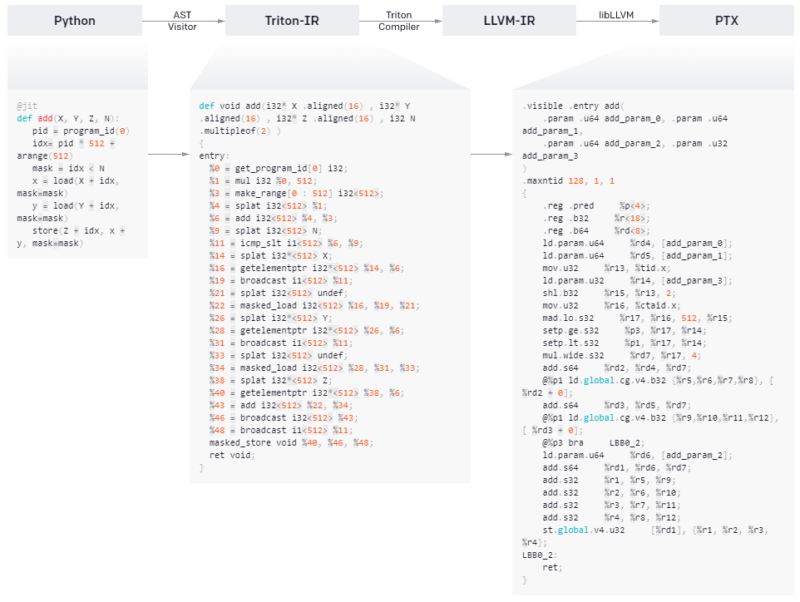
Tritonの高レベルアーキテクチャ
@triton.jitデコレータは、提供されたPython関数の抽象構文木(AST:Abstract Syntax Tree)を伝って、一般的なSSA構築アルゴリズムを使用してオンザフライでTriton-IRを生成することで機能します。
結果として得られるIRコードは、コンパイラバックエンドによって単純化、最適化、および自動的に並列化されてから、最近のNVIDIA GPUで実行するために高品質のLLVM-IR(最終的にはPTX)に変換されます。CPUとAMD社のGPUは現在サポートされていませんが、この制限に対処することを目的としたコミュニティの貢献を歓迎します。
コンパイラのバックエンド
Triton-IRを介してブロック化されたプログラム表現を使用すると、コンパイラがさまざまな重要なプログラムの最適化を自動的に実行できることがわかりました。例えば、計算量の多いブロックレベルの演算(tl.dotなど)の演算子を調べることで、データを共有メモリに自動的に隠し、標準の活性分析手法を使用して割り当て/同期することができます。

Tritonコンパイラは、計算量の多い操作で使用されるブロック変数の有効期間を分析することにより、共有メモリを割り当てます。
その一方、Tritonプログラムは効率的かつ自動的に以下の両方を並列化する事もできます
(1)SM間
異なるカーネルインスタンスを同時に実行する事ができます。
(2)SM内
各ブロックレベルの操作の反復空間を分析し、それを異なるSIMDユニット間で適切に分割する事ができます。
以下に示します。
貢献するには?
Tritonがコミュニティ主導のプロジェクトになることを目指しています。GitHubでリポジトリをフォークしてください!
私たちのチームに参加してTritonとGPUカーネルの改良に取り組むことに興味がある場合、OpenAIは採用活動をしていますよ!
3.Triton:ニューラルネットワーク用のGPUプログラミングを楽にする新言語関連リンク
1)openai.com
Introducing Triton: Open-Source GPU Programming for Neural Networks
2)github.com
openai / triton
NVIDIA / cutlass
Apache / tvm
3)triton-lang.org
Welcome to Triton’s documentation! — Triton documentation


Tritonを使った自動並列化
各ブロックレベルの操作は、ストリーミングマルチプロセッサ(SM:Streaming Multiprocessor)で利用可能なリソースを利用するために自動的に並列化される、ブロック化された反復空間を定義します。