
1.Falken:摸倣学習を使用して複雑なゲームを効率的にデバッグ(2/2)まとめ
・ゲーム開発者は使用するAPIの組み合わせからどのモデルを選択すべきかわかる
・FPS、TPS、レーシング、シューティングゲームなどで制御スキームをモデリング可
・開発者はゲームプレイのデモとシステムの確認をスムーズに切り替えることが可能
2.ゲーム開発と摸倣学習
以下、ai.googleblog.comより「Quickly Training Game-Playing Agents with Machine Learning」の意訳です。元記事の投稿は2021年6月29日、Leopold HallerさんとHernan Moraldoさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Alexander Jawfox on Unsplash
APIからニューラルネットワークへ
この高レベルのセマンティックAPIは、使いやすいだけでなく、開発中の特定のゲームにシステムを柔軟に適応させることもできます。
ゲーム開発者が採用したAPIの組み合わせにより、どのネットワークアーキテクチャを選択すべきかがわかります。APIの組み合わせがシステムが展開されているゲームタイプに関する情報を提供するためです。
例えば、アクションの結果は、ボタンとジョイスティックのどちらが使われているのかによって異なります。また、画像処理の手法を使用して観測を処理します。これは、エージェントがレイキャストで環境を調査した結果です。これは自動運転車がLIDARを使用して環境を調査する方法と似ています。
私たちのAPIは十分に汎用的であり、一人称ゲーム(first-person games)、カメラの相対コントロールを備えた三人称ゲーム(third-person games)、レーシングゲーム、ツインスティックシューティングゲームなどのゲームで多くの一般的な制御スキーム(動きを制御するアクション出力の構成など)のモデリングを可能にします。
3Dの動きと照準は、一般にゲームプレイの不可欠な側面であることが多いため、私達はこれらのゲームでは、照準、アプローチ、回避などの単純な動作を自動的に行うネットワークを作成します。
システムは、ゲームの制御スキームを分析して、そのゲーム内の「観測」と「アクション」を実行するニューラルネットワークレイヤーを作成することでこれを実現します。たとえば、ゲーム舞台内の物体の「位置と回転」は、自動的に「方向と距離」に変換されます。
「方向と距離」はゲーム内の実体をAIで制御する際に効率的であり、この変換は通常、学習の速度を上げ、学習したネットワークをより一般化するのに役立ちます。
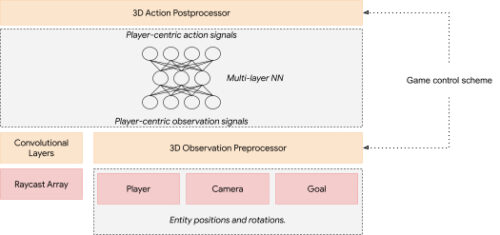
ジョイスティックコントロールとレイキャスト入力を使用してゲーム用に生成されたニューラルネットワーク
入力(赤)と制御スキームに応じて、システムは前処理レイヤーと後処理レイヤー(オレンジ)を生成します。
熟練者のプレイから学習
ニューラルネットワークアーキテクチャを生成した後、適切な学習アルゴリズムを選択してゲームをプレイするようにネットワークをトレーニングする必要があります。
報酬を最大化するためにMLポリシーを直接トレーニングする強化学習(RL:Reinforcement learning)は、ゲームを非常に上手にプレイするMLポリシーのトレーニングに使用されているため、当然の選択のように思われるかもしれません。ただし、RLアルゴリズムは、単一のゲーム実体から妥当な時間で収集できるデータよりも多くのデータを必要とする傾向があります。更に、異なるタイプのゲームで良好な結果を達成するには、ハイパーパラメータの調整と強力な機械学習に関する知識が必要になることがよくあります。
強化学習の代わりに、熟練者のゲームプレイの観察に基づいてMLポリシーをトレーニングする模倣学習(IL:Imitation Learning)が、私たちのユースケースに適していることがわかりました。エージェントが独自に適切なポリシーを発見する必要があるRLとは異なり、ILは人間の専門家の行動を再現するだけで済みます。ゲーム開発者とテスターはそれぞれのゲームのエキスパートであるため、ゲームのプレイ方法のデモンストレーションを簡単に提供できます。
DAggerアルゴリズムに触発されたILアプローチを使用します。これにより、ビデオゲームの最も魅力的な特質である「双方向性(interactivity)」を活用できます。
セマンティックAPIによってトレーニング時間とデータ要件が削減されたおかげで、トレーニングは事実上リアルタイムで可能になり、開発者はゲームプレイのデモンストレーションの提供とシステムの確認をスムーズに切り替えることができます。これにより、開発者がMLポリシーに継続的な修正を繰り返し提供する自然なフィードバックループが実現できます。
開発者の観点からは、問題のある動作のデモンストレーションまたは修正を提供することは、コントローラーを手に取ってゲームを開始するのと同じくらい簡単です。 完了したら、コントローラーを下に置き、MLポリシーの再生を確認できます。 その結果、リアルタイムで、インタラクティブで、非常に経験豊富で、多くの場合、面白みのあるトレーニング体験を少なからず得られます。

私たちのシステムで訓練されたFPSゲームのMLポリシー
結論
高レベルのセマンティックAPIとDAggerに触発されたインタラクティブなトレーニングフローを組み合わせたシステムを紹介しました。これにより、さまざまなジャンルのビデオゲームのテストに役立つMLポリシーのトレーニングが可能になります。
システム概要として、オープンソースでライブラリを公開しました。MLの専門知識は必要なく、テストアプリケーションのエージェントのトレーニングは、多くの場合、単一の開発者用マシンで1時間未満で完了できます。この研究が、利用しやすく、効果的で、楽しく使用できる実際のゲーム開発フローに展開できるML技術の開発を刺激するのに役立つことを願っています。
謝辞
プロジェクトのコアメンバーであるDexter Allen, Leopold Haller, Nathan Martz, Hernan Moraldo, Stewart Miles そして Hina Sakazakに感謝します。
トレーニングアルゴリズムはTF Agentによって提供され、デバイス上の推論はTF Liteによって提供されます。リサーチアドバイザーのOlivier Bachem, Erik Frey, そして Toby Pohlenと、有益なガイダンスとサポートを提供してくれたEugene Brevdo, Jared Duke, Oscar Ramirez そして Neal Wuに特に感謝します。
3.Falken:摸倣学習を使用して複雑なゲームを効率的にデバッグ(2/2)関連リンク
1)ai.googleblog.com
Quickly Training Game-Playing Agents with Machine Learning
2)github.com
google-research / falken

