
1.HuBERT:話言葉を音声から直接学習する自己教師あり特徴表現学習(2/2)まとめ
・HuBERTは完全に音声データだけでトレーニングされたNLPシステムを開発するのに役立つ
・AI音声アシスタントは人が発音するニュアンスや感情を考慮して対応できるようになる
・話し言葉のみの方言や言語をカバーする包括的なアプリケーションの構築にも役立つ
2.HuBERTの性能
以下、ai.facebook.comより「HuBERT: Self-supervised representation learning for speech recognition, generation, and compression」の意訳です。元記事は2021年6月15日、Abdelrahman Mohamedさん、Wei-Ning Hsuさん、Kushal Lakhotiaさんによる投稿です。
アイキャッチ画像はArtveeより「The Vision Of St. Hubert(1916)」 作者はEgon Schieleさんです。
HuBERTが標準的なLibriSpeech 960時間またはLibri-Light 60,000時間のいずれかで事前トレーニングされている場合、10分、1時間、10時間、100時間、960時間のすべての微調整サブセットで最先端のwav2vec 2.0パフォーマンスに匹敵するか、それを改善します。
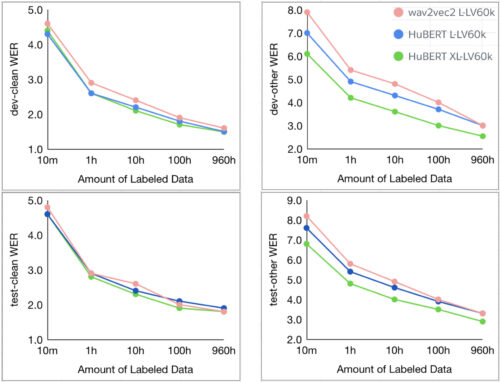
グラフは、LARGE(3億)とX-LARGE(10億)で事前トレーニングされた2つのモデルサイズでのHuBERTの結果を示しています。X-LARGEモデルは、60,000時間のLibri-Lightデータで事前トレーニングした場合、dev-otherおよびtest-other評価サブセットで最大19%および13%の相対的なWERの改善を示しています。
音声特徴表現学習の顕著な成功により、語彙リソースに依存することなく、音声信号を直接言語モデリングする事が可能になります。(教師あり学習用のラベル、テキストコーパス、または語彙の目録はありません)。これにより、非字句情報、つまり突然の一時停止や緊急の中断、バックグラウンドノイズをモデル化するための扉が開かれます。
私達のGenerative Spoken Language Modeling(GSLM)では、CPC、Wav2Vec2.0、およびHuBERTから学習した音声特徴表現を利用して音声を合成するための第一歩を踏み出しました。
離散化された潜在特徴表現でトレーニングされたユニット言語モデルにより、条件付きおよび条件なしの音声生成が可能になります。自動評価指標と人間による評価指標の両方で、HuBERTは、高性能の教師有り文字ベース言語モデルと品質が競合するサンプルを生成しました。
github(Generative Spoken Language Modeling from Raw Audio)で全てのシステムの生成された条件付きおよび条件なしのサンプルを聞くことができます。
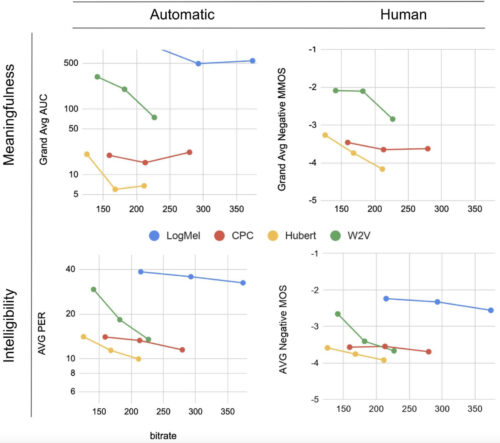
上のグラフは、言語生成に対するHuBERTのパフォーマンスを示しています。
音声圧縮については、私達の最近の論文「Speech Resynthesis from Discrete Disentangled Self-Supervised Representations」では、HuBERTを使用して、品質を低下させることなく365bpsのビットレートを達成しました。githubからHuBERTで圧縮したオーディオのサンプルを聞くことができます。
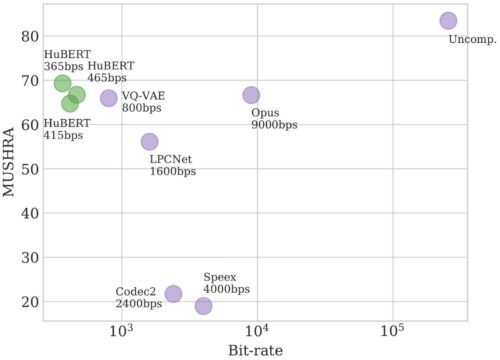
HuBERTは、非圧縮オーディオ(256kbps)の次に位置します。
アンカー(MUSHRA)主観テストを使用したマルチスティミュラステストの結果
HuBERTが重要な理由
HuBERTは、AI研究コミュニティが、文章に依存せず、完全に音声データだけでトレーニングされたNLPシステムを開発するのに役立ちます。
これにより、既存のNLPアプリケーションを任意の話し言葉の表現を使って充実させることができます。これはAI音声アシスタントが実際の人が発音するニュアンスや感情を考慮して対応する事を可能にします。
大量のラベル付きデータに依存せずに音声特徴表現を学習することも、新たな言語や対応領域が増え続ける産業用アプリケーションや製品にとって重要です。そして、AIコミュニティが、話し言葉のみの方言や言語をカバーする、より包括的なアプリケーションを構築するのに役立ちます。
3.HuBERT:話言葉を音声から直接学習する自己教師あり特徴表現学習(2/2)関連リンク
1)ai.facebook.com
HuBERT: Self-supervised representation learning for speech recognition, generation, and compression
2)arxiv.org
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
3)github.com
fairseq/examples/hubert/
4)speechbot.github.io
Generative Spoken Language Modeling from Raw Audio

