
1.MaX-DeepLab:デュアルパストランスフォーマーを使ってパノプティックセグメンテーションを直接実行(2/2)まとめ
・MaX-DeepLabはパノプティコンセグメンテーションを直接トレーニングできる初の手法
・マスクとクラスを直接予測するため多くの手動設計サブタスクが不要にできる
・COCOデータセットで最先端のボックスベースの手法に迫る性能のギャップを埋めた
2.MaX-DeepLabの性能
以下、ai.googleblog.comより「MaX-DeepLab: Dual-Path Transformers for End-to-End Panoptic Segmentation」の意訳です。元記事の投稿は2021年4月21日、Huiyu WangさんとLiang-Chieh Chenさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Raphael Andres on Unsplash
Dual-Path Transformer
従来のtransformer を畳み込みニューラルネットワーク(CNN)の上に積み重ねるのではなく、CNNをtransformer と組み合わせるためのデュアルパスフレームワークを提案します。
具体的には、Dual-Path Transformerブロックを使用して、任意のCNNレイヤーがグローバルメモリの読み取りと書き込みを行えるようにします。
私達が提案するこのブロックは、CNNパスとメモリパスの間で4種類すべてのattentionを採用可能で、CNNのどこにでも挿入できるため、任意の層でグローバルメモリとの通信が可能になります。
MaX-DeepLabは、マルチスケール特徴高解像度出力に集約するstacked-hourglassスタイルのデコーダーも採用しています。次に、出力にグローバルメモリ特徴が乗算され、マスクセットの予測が形成されます。マスクのクラスは、mask transformerの別のブランチで予測されます。
デュアルパストランスフォーマーアーキテクチャの概要
結果
最先端の境界ボックスを使用しない手法(Axial-DeepLab)と境界ボックスを使用する手法(DetectoRS)の両者に対して、最も困難なパノプティックセグメンテーションデータセットの1つであるCOCOでMaX-DeepLabを評価します。MaX-DeepLabは、テスト時間を増やす事なしで、test-devセットで51.3%PQの最先端のスコアを達成します。
| アプローチ | 手法名 | PQ値 |
| 境界ボックス未使用 | DETR | 46.0(-5.3) |
| DetectoRS | 49.6(-1.7) | |
| 境界ボックス使用 | Panoptic-DeepLab | 41.4(-9.9) |
| Axial-DeepLab | 44.2(-7.1) | |
| MaX-DeepLAb | 51.3 |
COCO test-devセットを使った比較
この結果は、境界ボックスを使用しない手法のAxial-DeepLabに対して7.1%PQ、使用するDetectoRSに対して1.7%PQ上回っており、ボックスベースの手法とボックスフリー手法のギャップを初めて埋めました。DETRとの一貫した比較のために、パラメーターの数とDETRの計算量に一致するMaX-DeepLabの軽量バージョンも評価しました。軽量のMaX-DeepLabは、valセットで3.3%PQ、test-devセットで3.0%PQだけDETRを上回っています。
更に、エンドツーエンドの定式化、モデルスケーリング、デュアルパスアーキテクチャ、および損失関数について、広範なアブレーション研究と分析を実行しました。また、MaX-DeepLabでは、DETRの非常に長いトレーニングスケジュールは必要ありません。
以下の図の例として、MaX-DeepLabは椅子に座っている犬を正しくセグメント化できています。
Axial-DeepLabは、オブジェクトの中心からのオフセットを算出する代替サブタスクに依存しています。そして、犬と椅子の中心が近いので失敗します。DetectoRSは、マスクではなくオブジェクト境界ボックスを代替サブタスクに使って分類を行います。椅子の境界ボックスの信頼度が低いため、椅子のマスクを背後の物体と混ぜ合わせてしまっています。
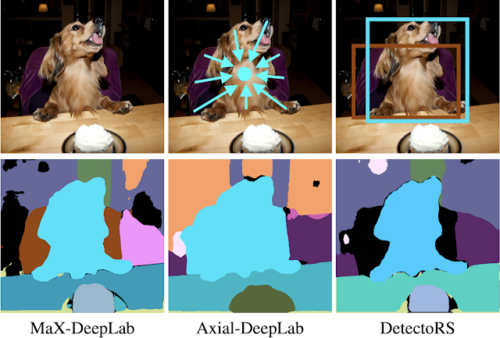
MaX-DeepLabと最先端のボックスフリーおよびボックスベースの手法のケーススタディ
別の例は、MaX-DeepLabが困難な条件で画像を正しくセグメント化できる事を示しています。

MaX-DeepLabは、重なり合うシマウマを正しくセグメント化できます。
シマウマ同士は似た境界ボックスを持ち、物体中心も近いため、このケースは他の手法でも困難です。(staticflickr.comよりCC BY-NC-ND 2.0ライセンス)
結論
パノプティコンセグメンテーションを直接トレーニングできることを初めて示しました。MaX-DeepLabは、mask transformerを使用してマスクとクラスを直接予測し、物体境界ボックス、モノのマージなど、多くの手動設計された事前設定の必要性を排除します。
PQスタイルの損失とデュアルパストランスフォーマーを備えたMaX-DeepLabは、挑戦的なCOCOデータセットで最先端の結果を達成し、ボックスベースの方法とボックスフリーの方法の間のギャップを埋めました。
謝辞
共著者のYukun Zhu, Hartwig Adam, そしてAlan Yuilleに感謝します。また、Maxwell Collins, Sergey Ioffe, Jiquan Ngiam, Siyuan Qiao, Chen Wei, Jieneng Chen、およびMobile Visionチームのサポートと貴重な議論に感謝します。
3.MaX-DeepLab:デュアルパストランスフォーマーを使ってパノプティックセグメンテーションを直接実行(2/2)関連リンク
1)ai.googleblog.com
MaX-DeepLab: Dual-Path Transformers for End-to-End Panoptic Segmentation
2)arxiv.org
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers

