
1.幅広い内容の質問に長文で回答可能な質問回答システムの進歩と課題(2/2)まとめ
・Routing TransformersとREALMに基づいた質問応答システムは従来のスコアを更新
・しかし既存のベンチマークには進歩を妨げるいくつかの問題がある事も判明した
・これらの問題を解決しLFQAタスクで有意義な進歩を遂げられるになることを願う
2.LFQAの課題
以下、ai.googleblog.comより「Progress and Challenges in Long-Form Open-Domain Question Answering」の意訳です。元記事の投稿は2021年3月23日、Aurko Royさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Camylla Battani on Unsplash
情報検索
長文形式質問回答(LFQA:Long-Form Question Answering)タスクにおけるRTモデルの有効性を実証するために、昨年夏にGoogleが発表した検索機構を組み込んだモデルであるREALMと組み合わせました。
REALMモデル(Guu et al 2020)は、最大内積探索を使用して、特定の検索文または質問に関連するWikipediaの記事を検索する検索ベースのモデルです。モデルは、Natural Questionsデータセットでfactoid型質問回答用に微調整されました。REALMは、BERTモデルを利用して質問の適切な特徴表現を学習し、SCANNを使用して質問の特徴表現とトピックの類似性が高いウィキペディアの記事を取得します。次に、これをエンドツーエンドでトレーニングして、QAタスクの対数尤度を最大化します。
対照的な損失(contrastive loss)を使用することにより、REALM検索の品質をさらに向上させます。この背後にある考え方は、質問の特徴表現をその真の回答の特徴表現に近づけ、ミニバッチ内の他の回答の特徴表現から遠ざかるように奨励することです。
これにより、システムがこの質問の特徴表現を使用して関連アイテムを取得するときに、真の回答に「類似した」記事が返されるようになります。この検索をcontrastive-REALMまたはc-REALMと呼びます。

LFQA用のRTとc-REALMシステムの組み合わせ
評価
KILTベンチマークの一部であり、公開されている唯一の大規模LFQAデータセットであるELI5データセットを使用して、長文形式の質問応答でモデルをテストしました。
KILTベンチマークは、Precision(R-Prec)を使用したテキスト検索と、ROUGE-Lを使用したテキスト生成を測定します。2つのスコアを組み合わせて、モデルのランキングを決定するKILTR-Lスコアを算出します。事前にトレーニングされたRTモデルを、KILT内のELI5データセットに対するc-REALMとともに微調整します。
私達の提出スコアは、ELI5での長文形式の質問回答のKILTリーダーボードを上回り、KILTR-Lの合計スコアは2.36です。リーダーボード上の他のモデルと同等の数のパラメーターを持ちながら、BART + DPRの以前のリーダーボードエントリ(KILT R-Lスコア1.9)を改善します。テキスト生成の品質に関しては、T5、BART + DPR、およびRAGに比べて、それぞれ+ 4.11、+ 5.78、および+ 9.14のRouge-Lスコアの改善が見られます。
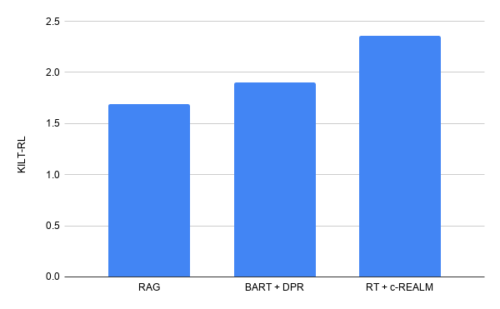
ELI5での長文形式の質問回答のKILTリーダーボードの結果
RTモデルが生成した文章の例
Boats are generally painted white for obvious reasons, as they are inexpensive and easy to clean. Ships are also often painted to provide a visible visual contrast to the sea. Boats also often have high visibility ports to allow for easy international trade. In addition, many boats have an air-breathing function that makes them easier to spot and stay afloat, which is a good thing if you’re a pirate or trying to get into some country’s waters. Lastly, many ships are built in the last few decades, so they are not as exotic looking as they were thirty years ago. And lastly, many ships are made out of materials that are easy to work with, and so many of them are painted white as a practical matter. There are many, many more reasons for why ships are white, but those are the ones I know of. I’m sure there are many other reasons, but those are the ones I know of. Edit: I forgot to mention that the other answers about visibility and easy to see ports are also true. Ships are painted to appear to be larger, and more expensive. That makes them appear more impressive, and so they are more likely to be bought by people who want to show off their wealth and status.
LFQAの進歩に向けたハードル
ただし、ここで説明したRTシステムは公開リーダーボードの上位ランクに位置しますが、モデルとELI5データセットの詳細な分析により、いくつかの懸念される傾向が明らかになりました。
トレーニングセット内では、提供されている質問の多くが言い換えから構成されてます。同様なトレーニングに関する質問に対するベストアンサーは27.4ROUGE-Lになります。
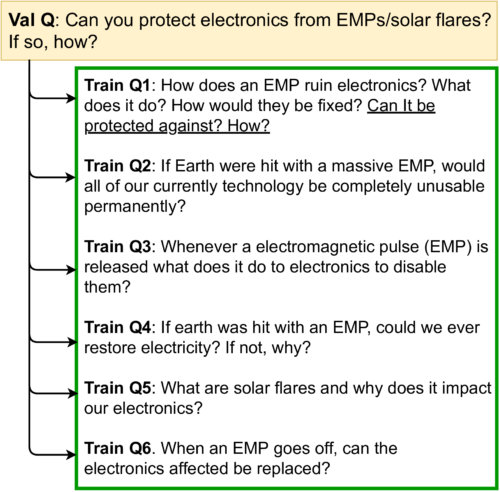
ランダムに無関係なトレーニングデータ内の質問への回答を取得するだけで、比較的高いROUGE-Lスコアが得られる事があります。その一方、定番的な真の回答は適当に生成された回答のスコアを下回ります。

関連するドキュメントではなくランダムなドキュメントに条件付けて回答を生成させても、事実の正確さに測定可能な影響を与えていません。出力が長いほど、ROUGE-Lスコアは高くなります。

モデルが実際に取得したドキュメントでテキスト生成を行っているという証拠はほとんど、またはまったく見つかりません。ウィキペディアからのランダム検索(つまり、ランダム検索+ RT)を使用したRTモデルの微調整は、c-REALM + RTモデルとほぼ同じように機能します。(24.2対24.4 ROUGE-L)
また、ELI5のトレーニング、検証、およびテストセット(いくつかの質問は互いに言い換えられています)に大きな重複があり、検索の必要性がない可能性があります。KILTベンチマークは、テキスト生成が実際に検索を使用することを確認せずに、検索と世代の品質を別々に測定します。
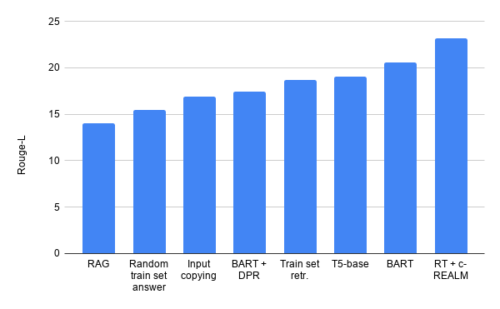
些細なベースラインは、RAGおよびBART + DPRよりも高いRouge-Lスコアを取得します。
更に、テキスト生成の品質を評価するために使用されるRouge-L基準に問題があり、ランダムなトレーニングセットを使った回答や入力文のコピーなどの些細で無意味なベースラインが比較的高いRouge-Lスコアを達成します(BART + DPRや RAG)。
結論
ELI5のKILTリーダーボードのトップであるRouting TransformersとREALMに基づく長い形式の質問応答システムを提案しました。ただし、詳細な分析により、ベンチマークを使用して意味のあるモデリングの進歩を通知することを妨げるいくつかの問題が明らかになります。コミュニティが協力してこれらの問題を解決し、研究者が正しい丘を登り、この挑戦的で重要なタスクで有意義な進歩を遂げられるようになることを願っています。
謝辞
Routing Transformerの作業は、Aurko Roy、Mohammad Saffar、Ashish Vaswani、DavidGrangierが関与するチームの取り組みです。オープンドメインの長文形式の質問応答に関するフォローアップ作業は、Kalpesh Krishna、Aurko Roy、およびMohitIyyerが関与するコラボレーションです。 Vidhisha Balachandran、Niki Parmar、Ashish Vaswaniのいくつかの有益な議論に感謝します。REALMチーム(Kenton Lee、Kelvin Guu、Ming-Wei Chang、Zora Tung)は、コードベースといくつかの有益なディスカッションを支援してくれました。これは、実験の改善に役立ちました。
ELI5トレインおよびテストセットで言い換えを検出するために使用されるQQP分類子を支援してくれたTuVuに感謝します。ROUGE-Lの境界をチェックするための有用な実験を提案してくれたJules Gagnon-Marchand and Sewon Minに感謝します。 最後に、プロジェクトのさまざまな段階で有益な議論と提案をしてくれたShufan Wang, Andrew Drozdov, Nader Akouryその他のUMassNLPグループに感謝します。
3.幅広い内容の質問に長文で回答可能な質問回答システムの進歩と課題(2/2)関連リンク
1)ai.googleblog.com
Progress and Challenges in Long-Form Open-Domain Question Answering
2)arxiv.org
Hurdles to Progress in Long-form Question Answering

