
1.その転移学習は本当に有用なのか?(2/3)まとめ
・大きなモデルの下位レイヤーでは学習による重みの変化が小さく特徴表現はかなり再利用される
・大きなモデルでも小さなモデルでも上位レイヤーでは重みの変化が大きく特徴表現はあまり再利用されない
・小さなモデルの下位レイヤーでは学習による重みの変化が大きく特徴表現は適度に再利用される
2.特徴表現の分析
以下、ai.googleblog.comより「Understanding Transfer Learning for Medical Imaging」の意訳です。元記事は2019年12月6日、Maithra RaghuさんとChiyuan Zhangさんによる投稿です。
特徴表現分析
次に、転移学習がニューラルネットワークによって学習される特徴表現等にどのような影響を与えるのかを調べました。
同程度に学習させた場合、転移学習を行ったネットワークはランダムな初期値からスタートとしたネットワークと異なった特徴表現になるのでしょうか?事前学習で得た知識は本当に再利用されているのでしょうか?
これらの質問に対する答えを見つけるために、本研究では、特定タスクを解決するために訓練された様々なニューラルネットワークの隠れ特徴表現(つまり、ネットワークの隠れ層で学習された特徴表現)を分析および比較しました。
この定量分析は、さまざまな隠れ層の複雑さと対応関係が明確でない事により、困難な場合があります。しかし、最近提案された正準相関分析(CCA)に基づく特異ベクトル正準相関分析(SVCCA:githubにコードおよびチュートリアルがあります)は、これらの課題を克服するのに役立ち、隠された特徴表現同士の類似性スコアを計算する事に使用できます。
「ランダムな初期値から学習したネットワーク」と「ImageNetで事前訓練した重みから学習したネットワーク」との間で特徴表現の類似性スコアを計算しました。類似性スコアは各ネットワークの最上位隠れ層(出力に一番近い層)の隠れ特徴表現のいくつかについて計算しています。
比較対象として、ランダムな初期値から学習させた2つのモデル同士の特徴表現の類似性スコアも計算しました。大規模なモデルの場合、「ランダムな初期値から学習した特徴表現同士の類似性」は「転移学習から学習した特徴表現とランダムな初期値から学習した特徴表現の類似性」よりもはるかに高い類似性を示します。小さいモデルの場合は、両ケースの特徴表現の類似性スコア間の重なり具合が大きくなります。
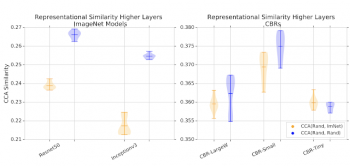
ランダムな初期値から訓練されたネットワークとImageNetで事前訓練された重みを初期値として訓練されたネットワーク(オレンジ)間の表現類似性スコア、及び比較基準となるランダムな初期値から訓練された2つの異なった特徴表現の類似性スコア(青)。値が大きいほど、類似性が高いことを示します。大きなモデルの場合、ランダムな初期値から学習した特徴表現同士は、転移学習を通じて学習した特徴表現よりもはるかに類似しています。これは、小さなモデルには当てはまりません。
大きなモデルと小さなモデルのこの違いの理由は、隠れ特徴表現を更に調査することで明らかになります。大きなモデルは、ランダムな初期値から学習を開始しても、学習による重みの変化が小さいのです。これを示すため、微調整を行った際に異なるレイヤー間で重みがどのように変わるかを追跡する実験を行いました。
論文では下記全ての実験結果を組み合わせて、医療画像タスクをトレーニングする際にどの程度特徴表現が変化するかを表にまとめました。(i)転移学習有無、(ii)モデルのサイズ、(iii)下位レイヤー/上位レイヤー
| 大きなモデルの下位レイヤー | 大きなモデルの上位レイヤー | 小さなモデルの下位レイヤー | 小さなモデルの上位レイヤー | |
| ランダムな初期化 | あまり変わらない | 大きく変わる | 大きく変わる | 大きく変わる |
| 転移学習 | あまり変わらない | 大きく変わる | 大きく変わる | 大きく変わる |
| 特徴表現はかなり再利用される | 特徴表現はあまり再利用されない | 特徴表現は適度に再利用される | 特徴表現はあまり再利用されない |
3.その転移学習は本当に有用なのか?(2/3)関連リンク
1)ai.googleblog.com
Understanding Transfer Learning for Medical Imaging
2)arxiv.org
Transfusion: Understanding Transfer Learning for Medical Imaging
3)github.com
google/svcca

コメント