
1.RecSim:推薦システムに強化学習を使うためのシミュレーションプラットフォーム(2/3)まとめ
・ほとんどの推薦システムは静的データセットを使用しておりユーザと実際に対話しているわけではい
・また推薦ポリシーそのものがユーザーの行動に長期的な累積的な影響を与える可能性がある
・RecSimはシミュレートされた環境でそのようなユーザー行動のモデル化も行っている
2.RecSimの概要
以下、ai.googleblog.comより「RecSim: A Configurable Simulation Platform for Recommender Systems」の意訳です。元記事は2019年11月19日、Martin MladenovさんとChih-wei Hsuさんによる投稿です。
強化学習と推薦システム
推薦システムに強化学習を適用する際の課題の1つは、ほとんどの推薦システムが静的データセットを使用して研究や開発および評価されている事です。現実世界のユーザと連続して繰り返し対話を行って、その反映しているわけではありません。
MovieLens 1Mなど、現実世界に対応したデータでさえ、新しく作成した推薦ポリシーが長期的にどのようなパフォーマンスになるか予測する事は(簡単に)出来るわけではありません。収集したデータ内には、現実世界のユーザーの選択に影響する多くの要因が記録されていないためです。
これにより、基本的な強化学習アルゴリズムでさえ評価も非常に困難になります。新しい推薦ポリシーが長期的にどのような結果をもたらすか推論する場合は特にです。調査によると、推薦ポリシーの変更はユーザーの行動に長期的な、累積的な影響を与える可能性があります。
シミュレートされた環境でそのようなユーザーの行動をモデル化し、強化学習を使用するモデルを含む新しい推奨アルゴリズムを考案およびテストできるようになれば、このような問題の研究開発サイクルを大幅に加速できます。
RecSimの概要
RecSimは、推薦エージェントが「ユーザーモデル」、「ドキュメントモデル」、「ユーザー選択モデル」で構成される環境と対話する事をシミュレートします。
推薦エージェントは、ドキュメントのセットまたはリスト(訳注:slates、スレートと呼ばれ、元々の単語の意味は石板とか候補者リストとかそんな感じです)をユーザーに推薦することで環境と対話します。また、シミュレートされた個々のユーザーとドキュメントの観察可能な特徴にアクセスして何を推奨するかを決定しています。
ユーザーモデルは、(設定により変更可能な)ユーザーの特徴(例えば、興味の対象や満足度などの潜在的な特徴。ユーザーの人口統計などの観察可能な特徴。訪問頻度や時間の予算などの行動の特徴)の分布からユーザーをサンプリングしています。
ドキュメントモデルは、潜在的な特徴(例:品質など)と観察可能な特徴(例:長さや人気度)の両方を、ドキュメント特徴の事前確率からサンプリングします。この事前確率は、RecSimの他のすべてのコンポーネントと同様、シミュレーション開発者がアプリケーションデータから通知(または学習)する事で指定できます。
ユーザーモデルとドキュメントモデルの両方の特徴の可観測性レベルはカスタマイズ可能です。エージェントがユーザーにドキュメントを推奨した時、推奨に対する応答はユーザー選択モデルによって決定されます。ユーザー選択モデルは、観察可能なドキュメント特徴と全てのユーザー特徴にアクセスできます。
ユーザーの応答の他の側面(例:推薦事項を実施するまでにかかった時間)は、ドキュメントのトピックや品質など、潜在的なドキュメントの特徴に依存する場合があります。
ドキュメントが一度消費されると、ユーザーの満足度や関心が変わる可能性があるため、ユーザーの状態は設定変更可能な「ユーザー遷移モデル」を介して遷移します。
RecSimは、研究者や実践者にとって関心のあるユーザー行動の特定の側面を簡単に作成し、他の側面を無視する機能を提供します。これにより、興味のある新しい現象用に設計されたモデリングとアルゴリズム手法に焦点を当てる重要な機能を提供できます。(後述の2つのアプリケーションで説明します)
このタイプの抽象化は、多くの場合、科学的モデリングにとって重要です。従って、ユーザーの行動の全ての要素に関して忠実度の高いシミュレーションを行う事は、RecSimの明確な目標ではありません。
とはいえ、特定の場合に「sim-to-real(シミュレーションから現実への)」転送をサポートするプラットフォームとしても機能することを期待しています(以下を参照)。
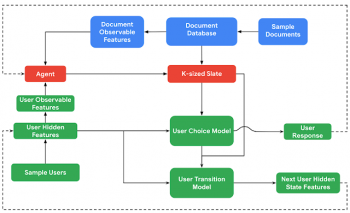
RecSimのコンポーネントを介したデータフロー。 色は、さまざまなモデルコンポーネントを表します。ユーザーモデルとユーザー選択モデルは緑、ドキュメントモデルは青、推薦エージェントは赤です。
3.RecSim:推薦システムに強化学習を使うためのシミュレーションプラットフォーム(2/3)関連リンク
1)ai.googleblog.com
RecSim: A Configurable Simulation Platform for Recommender Systems
2)arxiv.org
RecSim: A Configurable Simulation Platform for Recommender Systems
3)github.com
google-research/recsim
4)ai.google
SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets

コメント