
1.単眼カメラの映像から教師なし学習で物体までの距離を正確に測定(2/2)まとめ
・今回の手法ではエゴモーションも非常に正確に予測できた
・更にはあるデータセットで学習させたモデルを他のセットで更に洗練させる事もできた
・屋外データで学んだモデルを屋内データで洗練させるなど応用範囲が広い
2.オンラインリファイメントによる洗練学習
以下、ai.googleblog.comより「A Structured Approach to Unsupervised Depth Learning from Monocular Videos」の意訳です。元記事は2018年11月27日、Anelia Angelovaさんによる投稿です。本記事を読むとテスラ等の半自動運転車が静止している車に突っ込む事故の原因が理解できます。今回公開された手法が応用されると自動運転車の衝突事故は減るのだろうな、と思います。前半記事はこちら。
エゴモーション
私達の研究は、エゴモーション(自分自身の動き)についても他の最先端の研究の中でベストな結果を出しました。エゴモーションは自律型ロボットにとって重要です。エゴモーションの推定ができなければ、移動するロボットの位置を特定する事が出来ません。
以下のビデオは、エゴモーションから得られた推定速度と推定回転角を視覚化しています。奥行情報もエゴモーションも共にスカラ値ですが、減速と停止時に相対速度を推定できている事がわかります。
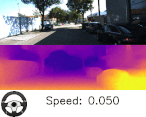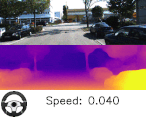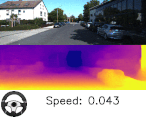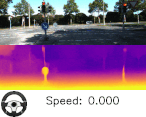
奥行情報とエゴモーションの予測。下部のスピードメータとハンドルが、車が曲がった時や赤信号で停止しているときどのように表示されるかを見て、エゴモーションの予測精度を実感してください。
ドメイン間転送
学習アルゴリズムで重視される事は、学習時の環境と異なる未知の環境に移動したときにどこまで性能を発揮できるかです。今回の研究では、新しいデータを収集しながらオンラインで学習も継続するオンラインリファイメント(refinement:精練)アプローチをさらに紹介します。以下は、Cityscapesデータセットで学習した後にKITTIデータセットを用いてオンラインリファイメントを行って、改善された奥行情報の例です。
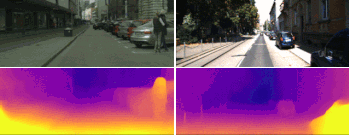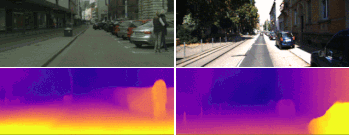
Cityscapesデータセットで学習した後にKITTIデータセットでオンラインリファイメントした結果。下段の図は、学習モデルの予測と学習モデルをオンラインリファイメントした後の奥行情報。オンラインリファイメントによって風景内の物体のアウトラインや奥行情報の精度が向上しています。
我々はさらに大きく異なったデータセットでも実験しました。例えば、Fetch robot(倉庫用ロボットメーカーのロボット)によって撮影された屋内データセットです。学習は市街地を走行する自動車から撮影されたCityscapesデータセットで行われたので、当然の事ながら、これらの2つのデータセット間には大きな相違があります。それにもかかわらず、私達は、オンライン学習テクニックにより、基準となるベースラインよりも高い精度で奥行情報を得る事ができました。
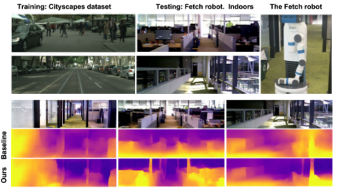
Cityscapes(移動する車から撮影した町中の風景のデータセット)で学習した学習モデルをFetch robotが屋内で撮影したデータセットでオンラインリファイメントした結果。一番下の行は、オンラインリファイメントの結果、奥行情報が洗練された事を示しています。
まとめると、今回の手法は単眼カメラの映像から奥行情報とエゴモーションを教師無し学習し、非常に動きのあるシーンで起こる問題を解決しています。高価格なステレオカメラシステムに匹敵する高品質な奥行情報とエゴモーション認識を達成し、学習プロセスに構造化を取り入れるというアイディアを推進します。より具体的には、私達が提案する単眼カメラ映像のみからの奥行きとエゴモーションを教師無し学習するコンビネーションは、シンプルなビデオ映像を使って教師無し学習できるだけでなく、他のデータセットにも応用できます。
謝辞
この研究は、Vincent Casser、Soeren Pirk、Reza Mahjourian、Anelia Angelovaによって行われました。 Ayzaan Wahid氏に、データ収集を手伝ってくれたMartin WickeとVincent Vanhouckeのサポートと励ましに感謝したいと思います。
(単眼カメラの映像から教師なし学習で物体までの距離を正確に測定(1/2)からの続きです)
3.単眼カメラの映像から教師なし学習で物体までの距離を正確に測定(1/2)まとめ
1)ai.googleblog.com
A Structured Approach to Unsupervised Depth Learning from Monocular Videos
2)arxiv.org
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos

コメント