
1.Flan-U-PaLM:わずかな追加計算で大規模言語モデルの性能を向上(1/2)まとめ
・巨大言語モデルを学習させるためには膨大な計算資源を必要でハードルが高い
・膨大な計算資源を使わずに既存モデルを大幅に改善する2つの手法を提案
・UL2Rは少ない計算量でUL2目的による事前学習を継続して性能を上げる手法
2.UL2Rとは?
以下、ai.googleblog.comより「Better Language Models Without Massive Compute」の意訳です。元記事は2022年11月29日、Jason WeiさんとYi Tayさんによる投稿です。
アイキャッチ画像はstable diffusion2.0のDreamBooth拡張の生成で、トトロやニコラス・ケイジと比較するとプロンプトで構成を指示する事が非常に困難で、もうお手上げになってナウシカの顔だけ並べたもはや本文とは関係ないイラスト。
近年、言語モデル(LM:Language Models)は自然言語処理(NLP:natural language processing)の研究においてより顕著になり、また、実用上もますます大きな影響を与えるようになってきています。言語モデルの規模の拡大は、様々なNLPタスクのパフォーマンスを向上させることが示されています。
例えば、言語モデルをスケールアップすると、7桁以上のモデルサイズで単語予測性能(perplexity)が向上し、モデルスケールの結果、多段階推論のような新しい能力が生じることが観察されています。しかし、スケーリングを続ける上での課題として、新しく大きなモデルを学習させるためには、膨大な計算資源を必要とすることが挙げられます。さらに、新しいモデルはゼロから学習されることが多く、以前に存在したモデルからの重みを活用することができません。
本ブログでは、膨大な計算資源を使わずに既存の言語モデルを大幅に改善する、2つの相補的な方法を探ります。
まず「Transcending Scaling Laws with 0.1% Extra Compute」では、Mixed-of-Denoisersを用いた軽量な二段階事前学習であるUL2Rを紹介します。UL2Rは、様々なタスクで性能を向上させ、以前はランダムな性能に近かったタスクで、創発的に性能を引き出すことも可能です。
次に「Scaling Instruction-Finetuned Language Models」では、指示(instructions)として表現されるデータセットに対して言語モデルの微調整を行う方法を研究しています。私達はこの手法を「Flan」と呼んでいます。
この手法は、性能を向上させるだけでなく、プロンプトのエンジニアリングをせずともユーザー入力に対する言語モデルの使い勝手を向上させます。
最後に、FlanとUL2Rを補完する手法として、Flan-U-PaLM 540Bと呼ばれるモデルを作成し、困難な評価ベンチマークにおいて、これらの手法を適用していないPaLM 540Bモデルより10%高い性能を示すことを示します。
UL2Rトレーニング
伝統的に、ほとんどの言語モデルは、モデルが文章内の次の単語を予測することを目的に学習させる因果言語モデリング(causal language modeling)や、破損させた文章の一部を元の文に復元する事を学習させるノイズ除去(denoising)目的のいずれかで事前に訓練されています。
因果言語モデリングには、例えば、GPT-3やPaLM、ノイズ除去目的にはT5などがあります。
因果言語モデルは長文生成に優れ、ノイズ除去目的で学習したLMは微調整に優れるというトレードオフがありますが、先行研究において、両方の目的を含むMixed-of-Denoisers目的が、両方のシナリオでより良い性能を示すことを実証しています。
しかし、異なる目的に対して大規模な言語モデルを一から事前学習させることは、計算上不可能です。そこで、私達はUL2 Repair(UL2R)を提案します。これは、比較的少ない計算量でUL2目的による事前学習を継続する追加ステージです。UL2RをPaLMに適用し、得られた新しい言語モデルをU-PaLMと呼んでいます。
実証評価では、わずかなUL2学習でスケーリングカーブが大幅に改善されることを確認しました。例えば、PaLM 540Bの中間チェックポイントでUL2Rを用いると、2倍少ない計算量(440万 TPUv4 時間分の差)でPaLM 540Bの最終チェックポイントの性能に到達することが示されました。もちろん、最終的なPaLM 540BのチェックポイントにUL2Rを適用した場合も、論文にあるように大幅な性能向上を実現しています。
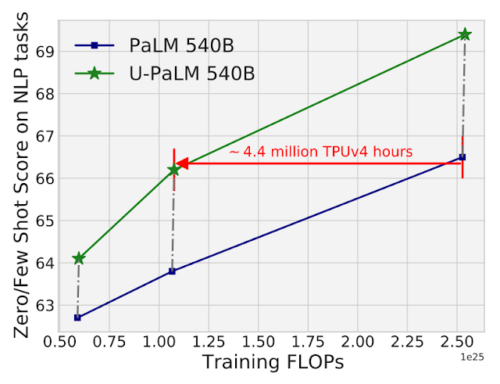
26のNLPベンチマーク(論文中の表8に記載)に対するPaLM 540BとU-PaLM 540Bの計算量対モデル性能の図。U-PaLM 540Bは、PaLMの学習を継続することで、非常に少ない計算量で、大幅な性能向上を実現しています。
UL2Rを使用することで観測されたもう一つの利点は、いくつかのタスクにおいて、純粋に因果関係言語モデリング目的で学習したモデルよりも性能がはるかに優れていることです。
例えば、BIG-Benchのタスクの中には、「創発的能力(emergent abilities)」、つまり、十分に大きな言語モデルにおいてのみ観測される能力として説明されているものが多数あります。このような能力は、LMの規模を大きくすることで発見されるのが一般的ですが、UL2RはLMの規模を大きくしなくても、実際に能力を引き出すことができることがわかりました。
例えば、BIG-BenchのNavigateタスク(モデルの状態追跡能力を測定)では、学習FLOPsが1023以下のU-PaLM以外のモデルは、ほぼランダムな性能しか達成できません。U-PaLMの性能はそれを10ポイント以上上回っています。
もう一つの例は、BIG-BenchのSnarksタスクです。これは、モデルの皮肉検出能力を測定するタスクです。ここでも、1024学習FLOPs未満のモデルはすべてほぼランダムな性能を達成しているのに対し、U-PaLMは8Bと62Bのモデルでもそれを大きく上回る性能を達成しています。
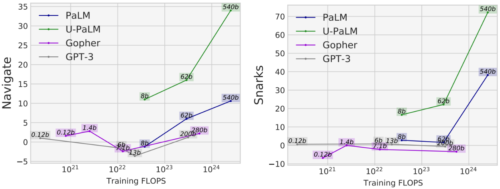
BIG-Benchで創発的な性能を示した2つの能力に対して、U-PaLMはUL2R目的語を使用することにより、より小さなモデルサイズで創発を達成しました。
3.Flan-U-PaLM:わずかな追加計算で大規模言語モデルの性能を向上(1/2)関連リンク
1)ai.googleblog.com
Better Language Models Without Massive Compute
2)arxiv.org
Transcending Scaling Laws with 0.1% Extra Compute
Scaling Instruction-Finetuned Language Models

