
1.Plex:何をすればディープラーニングの信頼性を高める事が出来るのか?(2/2)まとめ
・Plexは各サブモデルが予測を行って集約することでより効率的なアンサンブルを行う
・Plexはタスク毎にチューニングせずともモデルの出力そのままで全タスクで高い性能を達成
・ViT-Plexラベル効率が高くアクティブラーニングで効率的に少量データで学習が可能
2.Plexの性能
以下、ai.googleblog.comより「ai.googleblog.com」の意訳です。元記事は2022年7月14日、Dustin TranさんとBalaji Lakshminarayananさんによる投稿です。
アイキャッチ画像のクレジットはlatent diffusionでプロンプトはPlex。
Plex: 視覚と言語のための事前学習済大規模モデル拡張
信頼性を向上させるため、視覚(ViT)と言語(T5)のそれぞれについて、事前に学習した大規模なモデルを基に、ViT-PlexとT5-Plexを開発しました。
Plexの主な特徴は、各サブモデルが予測を行い、それを集約することで、より効率的なアンサンブルを行うことです。さらに、Plexは各アーキテクチャーの線形最終層(linear last layer)をガウス過程または不均一分散層(heteroscedastic layer)と入れ替えることで、予測の不確実性をより適切に表現しています。
これらのアイデアは、ImageNet規模でゼロから訓練されたモデルで非常にうまく機能することがわかりました。視覚(ViT-Plex L)では3億2500万パラメータまで、言語(T5-Plex L)では10億パラメータまで、事前学習データセットサイズは40億サンプルまで、様々なサイズのモデルを学習させます。
下図は、特定のタスクに対するPlexの性能を、既存の最先端技術と比較したものです。各タスクでトップクラスの性能を持つモデルは、通常、その問題に対して高度に最適化した特殊なモデルです。Plexは40のデータセットの多くで最先端を達成しています。重要なのは、Plexが、タスクごとにカスタム設計やチューニングをすることなく、モデルの出力をそのまま用いて、すべてのタスクで高い性能を達成したことです。
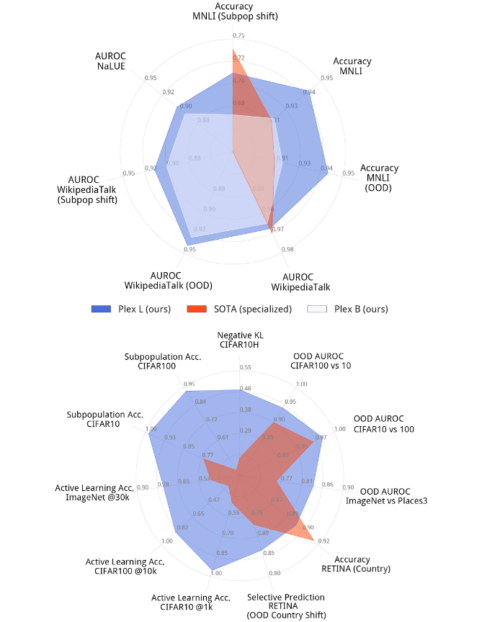
T5-Plex(上)とViT-Plex(下)の最大モデルを信頼性タスクのセットで評価し、特化型の最先端モデルとの比較しています、スポークには様々なタスクが表示され、様々なデータセットにおける指標のパフォーマンスが定量化されています。
さまざまな信頼性タスクにおけるPlexの動作
Plexの信頼性タスクの一部を紹介します。
オープンセット認識
モデルがサポートしていない入力があるために、モデルが予測を延期しなければならない場合におけるPlexの出力を示します。このタスクはオープンセット認識(open set recognition)として知られています。ここで、予測性能は、モデルが特定の予測を行うことを控える、より大きな意思決定シナリオの一部です。次の図では、構造化されたオープンセット認識を示しています。Plex は複数の出力を返し、モデルが不確実であり、分布外である可能性が高い出力の特定の部分を通知します
。

構造化されたオープンセット認識により、モデルはニュアンスを持つ説明を提供することができます。ここでは、T5-Plex Lは、きめ細かなレベルの分布外ケースを認識することができます。例えば、リクエストされた粗い領域(銀行、メディア、生産性など)や領域はサポートされているが意図がサポートされていないケースなど
ラベルの不確実性
実世界のデータセットでは、各入力に対する真実のラベルの背後に、固有の曖昧さが存在することがよくあります。例えば、これは与えられた画像に対する人間の評価者のあいまいさによって生じるかもしれません。このような場合、人間の知覚的不確実性の完全な分布をモデルで表現することが望まれます。以下に、私達が構築した、真実のラベル分布を提供するImageNetの亜種からの例で、Plexを紹介します。

ラベルの不確実性に対応するPlex
ViT-Plex Lは、私達が構築したImageNet ReaL-Hというデータセットを用いて、画像ラベルに内在する曖昧さ(確率分布)を捉える能力を実証しています。
アクティブラーニング
固定されたデータポイントのセットを通して学習するだけでなく、最初にどのデータポイントから学習すべきかを知り、関与する大規模モデルの能力を調べました。
このようなタスクはアクティブラーニングとして知られており、各トレーニングステップにおいて、モデルはラベルの付いていないデータポイントのプールから有望な入力を選択し、それを基に学習を行います。この手順では、モデルのラベル効率を評価します。ラベル注釈が少ない場合、使用するラベル付きデータの数を最小限に抑えながら、性能を最大化することが望まれます。Plexは、事前学習を行わない場合と比較して、同じモデルアーキテクチャで大幅な性能向上を達成しました。また、少ない学習例でも、10万事例で63%の精度に達する最先端の事前学習済み手法であるBASEを凌駕する性能を発揮します。
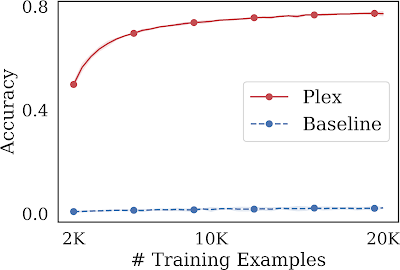
ImageNet1Kでのアクティブラーニング
ViT-Plex Lは、事前トレーニングを活用しないベースラインと比較して、ラベル効率が高くなっています。 また、アクティブラーニングのデータ取得戦略は、ランダムにデータポイントを均一に選択するよりも効果的であることがわかりました。
詳細はこちら
私たちの論文と、2022年7月23日に開催されるICML 2022プレトレーニングワークショップでのこの作業に関するコントリビュートトークをチェックしてください。この方向でのさらなる研究を奨励するため、Uncertainty Baselinesの一部として、学習と評価のためのすべてのコードをオープンソースにしています。また、ViT-Plexモデルのチェックポイントの使い方を紹介するデモも提供しています。レイヤーとメソッドの実装にはEdward2が使用されています。
謝辞
Andreas Kirsch, Clara Huiyi Hu, Du Phan, D. Sculley, Honglin Yuan, Jasper Snoek, Jeremiah Liu, Jie Ren, Joost van Amersfoort, Karan Singhal, Kehang Han, Kelly Buchanan, Kevin Murphy, Mark Collier, Mike Dusenberry, Neil Band, Nithum Thain, Rodolphe Jenatton, Tim G. J. Rudner, Yarin Gal, Zachary Nado, Zelda Mariet, Zi Wang, そしてZoubin Ghahramaniなど、プロジェクトと論文に貢献してくれたすべての共著者に感謝します。
また、Anusha Ramesh、Ben Adlam、Dilip Krishnan、Ed Chi、Neil Houlsby、Rif A. Saurous、Sharat Chikkerurの有益なフィードバックに感謝し、Tom SmallとAjay Nainaniには視覚化を支援してくれたことに感謝します。
3.Plex:何をすればディープラーニングの信頼性を高める事が出来るのか?(2/2)関連リンク
1)ai.googleblog.com
Towards Reliability in Deep Learning Systems
2)arxiv.org
Plex: Towards Reliability using Pretrained Large Model Extensions
3)goo.gle
plex-code

