1.Nested Hierarchical Transformer:ViTに数行のコードを加えるだけでデータ効率を大幅に向上(3/3)まとめ
・階層的アーキテクチャは空間的な関係を保持しておりCAMを適用して解釈が可能
・モデルの収束速度が大幅に向上し希望精度に達するまでの学習時間を大幅に短縮可能
・生成器にも応用可能であり訓練の容易性、収束速度、FIDスコアが向上する事が判明
2.収束速度の向上
以下、ai.googleblog.comより「Nested Hierarchical Transformer: Towards Accurate, Data-Efficient, and Interpretable Visual Understanding」の意訳です。元記事は2022年2月9日、Zizhao Zhangさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Edvard Alexander Rølvaag on Unsplash
第二に、オリジナルのViTとは異なり、私たちの採用した階層的アーキテクチャは、学習した特徴表現の空間的な関係を保持している事です。
上位層は入力画像の低解像度特徴表現マップを出力します。これにより、モデルは、最上位層で学習した特徴表現にクラスアテンションマップ(CAM:Class Attention Map)を適用する事が可能になり、Attentionに基づく解釈を容易に行うことを可能にします。
そのため、画像に付与されたラベルだけで高品質な弱い教師あり物体位置推定が可能となります。例として下図を参照してください。
収束速度のメリット
この設計では、特徴学習は局所的範囲で独立に行われ、特徴の抽象化は集計関数の内部で行われます。この設計とシンプルな実装は、視覚分類以外の視覚理解タスクにも十分対応できる汎用性を持っています。また、モデルの収束速度が大幅に向上し、希望する最大精度に達するまでの学習時間が大幅に短縮されます。
私たちはこの利点を2つの方法で検証しました。まず、オリジナルのViT構造と本手法をImageNetの精度で比較します。
総トレーニングエポック数を変えて比較した結果は下図の左側に示されており、オリジナルのViTよりもはるかに速い収束を示し、例えば、総トレーニングエポック数が30のViTよりも約20%精度が向上していることが分かります。
第二に、ViTベースのモデルの学習は、画像生成タスクに使用するには収束と速度の問題から困難であるため、無条件に画像生成タスクを実施できるようにアーキテクチャを変更しました。
このような生成器は、提案したアーキテクチャを置き換えることで簡単に作ることができます。入力はembeddingベクトル、出力はRGBチャンネルのフル画像、ブロック集約はPixel Shufflingでサポートされるブロック非集約コンポーネントで置き換えられます。
驚くべきことに、私たちの生成器は訓練が容易であり、容量比較が可能なSAGANよりも収束速度が速く、FIDスコア(生成された画像が実画像にどれだけ似ているかを示す)も優れていることが分かりました。
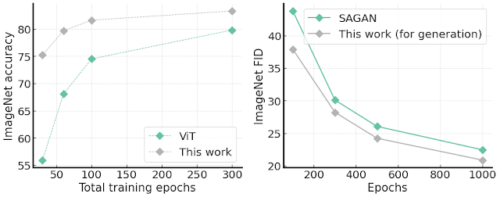
左:ImageNetの精度を、標準的なViTアーキテクチャと比較し、総トレーニングエポック数を変化させた図
右:ImageNet 64×64画像生成のFIDスコア(低いほど良い)、1000エポックの単一学習によるもの
両タスクにおいて、本手法は収束速度に優れていることがわかります。
まとめ
本研究では、特徴表現学習と特徴情報抽出を切り離したシンプルな入れ子階層構造(nested hierarchy design)を用いると、勾配ベースのクラスを意識した新しい木構造探索手法により、特徴表現の解釈可能性を向上させる事が出来る事を示しました。
さらに、このアーキテクチャは、分類タスクだけでなく、画像生成タスクにおいても収束性を向上させます。本提案は集約機能に着目したものであり、self-attentionを用いた先進的なアーキテクチャ設計とは異なるものです。
この新しい研究が、高解像度画像生成への本研究の採用のように、将来のアーキテクチャ設計者が、より解釈しやすく、データ効率の良いViTベースの視覚理解モデルの探求を促すことを期待しています。また、本研究の画像分類部分のソースコードも公開しています。
謝辞
Han Zhang, Long Zhao, Ting Chen, Sercan Arik, Tomas Pfisterを含む他の共著者の貢献に感謝します。また、Xiaohua Zhai, Jeremy Kubica, Kihyuk Sohn, そして Madeleine Udellにはこの研究に対する貴重なフィードバックをいただきました。
3.Nested Hierarchical Transformer:ViTに数行のコードを加えるだけでデータ効率を大幅に向上(3/3)関連リンク
1)ai.googleblog.com
Nested Hierarchical Transformer: Towards Accurate, Data-Efficient, and Interpretable Visual Understanding
2)arxiv.org
Nested Hierarchical Transformer: Towards Accurate, Data-Efficient and Interpretable Visual Understanding
3)github.com
google-research / nested-transformer

CAMを使ってattentionを可視化したもの。暖色系部分が高い数値です