
1.HPP:ロボット同士が待ち合わせできるようにするモデルベース強化学習(3/3)まとめ
・HPPを使用すると、エージェントは軌道を予測して調整し、調整ミスを回避できる
・HPPは追加のトレーニングなしで現実の世界に直接転移させる事が出来る
・ノイズの多いセンサーと不完全なコントローラーが搭載された現実世界の分散型タスクに応用可
2.HPPの能力
以下、ai.googleblog.comより「Model-Based RL for Decentralized Multi-agent Navigation」の意訳です。元記事の投稿は2021年4月28日、Rose E. WangさんとAleksandra Faustさんによる投稿です。
アイキャッチ画像のクレジットはPhoto by Matthieu Collin on Unsplash。
目標位置の調整と選択
各エージェントが持つモデルベースのRLプランナーは、学習済み予測器を使用して、展開先の環境でエージェントを待ち合わせ場所に導きます。プランナーは、待ち合わせタスクを完了するために、他のエージェントの動きを考慮に入れます。
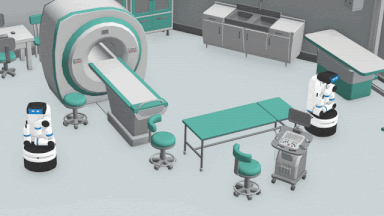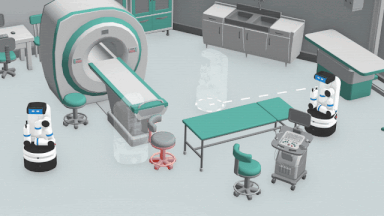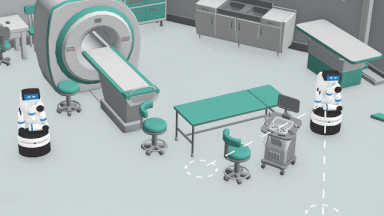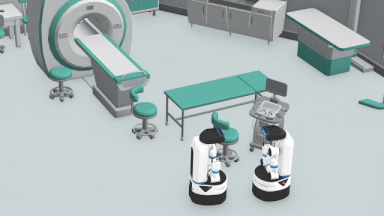
HPPの概要
各ロボットは、いくつかの潜在的な待ち合わせポイントを個別に検討し、エージェントが到達できると信じている距離に基づいて各ポイントを評価します。
この論理的思考を実現するために、各エージェントは一連の潜在的な目標を個別にサンプリングし、成功する可能性が最も高いと思われる目標を選択します。
このプロセスは、一元化されたプランナーの制御下で動く架空のエージェントを効果的にシミュレートしています。予測モデルを使用して、固定された目標に移動するエージェントの軌道を予測する事でこれを行います。
提案された目標位置を条件として、アルゴリズムは、将来のエージェントのポーズを予測します。この予測は予測モデルが順次投入する予測から生成されます。
次に、予想されたシステム状態をスコアリングすることにより、各目標位置が評価されます。この評価にはエージェントを近づける目標を優先するタスク報酬を使用します。
クロスエントロピー法(CEM:cross-entropy method)によるこれらの目標位置評価を使って、潜在的な待ち合わせポイントの確信分布(belief)の更新を行います。
最後に、エージェントのプランナーは、この新しい確信分布から自分自身の目標位置を選択し、この目標をエージェントの制御モジュールに渡します。
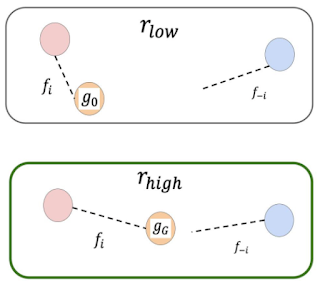
目標評価の簡単な図
シミュレートされた軌道の終わりに、エージェント(左の赤、右の青)は互いに遠く(上)または近く(下)に位置します。下の画像の目標は、上の目標よりも優れています。これは、エージェントが互いに近くなるためです。
結果
HPPを、実際の環境とシミュレートされた環境が混在するいくつかのベースラインと比較しました。MADDPG(学習ベース)、CEMを使用したRRT(計画)、およびエージェントが落ち合う場所を選択するために経験側を使用する一元化された比較対象手法

評価環境
それぞれが、エージェントの制御ポリシーおよび予測モジュールのトレーニング環境から独立しています。
この評価結果から判明した2つのポイントがあります。1つは、HPPを使用すると、エージェントが軌道を予測して調整し、調整ミスを回避できることです。例えば、

2つ目のポイントは、HPPが追加のトレーニングなしで直接現実の世界に転移出来る事です。 例えば:
![]()
結論
本研究は、分散型マルチエージェントの動作を調整するモデルベースのRLアプローチであるHPPを紹介しました。
エージェントはまず、自分とチームメートがどこに行くのかを自分のセンサーを使って予測し、共通の目標を決定してナビゲートすることを学びます。私たちの実験結果は、この方法が新しい環境に一般化し、他のエージェントのダイナミクスについて何も仮定せず、誤りを処理可能である事を示しています。
これは、ノイズの多いセンサーと不完全なコントローラーを使用した分散型タスクの現実世界の例として、より大規模なマルチエージェント研究コミュニティにとって興味深いかもしれません。例えば、モーションプランニングコミュニティにとってプランナーとコントローラーの間で閉じたループを持つ学習ベースの計画システムの例として、RLコミュニティには階層的な自己教師予測を持つモデルベースRLの例としてです。
謝辞
この調査は、Rose E. Wang, J. Chase Kew, Dennis Lee, Tsang-Wei Edward Lee, Tingnan Zhang, Brian Ichter, Jie Tan, Aleksandra Faustによって行われました。Michael Everett, Oscar Ramirez及びIgor Mordatchに洞察に満ちた議論を提供してくれた事に特に感謝をします。
3.HPP:ロボット同士が待ち合わせできるようにするモデルベース強化学習(3/3)関連リンク
1)ai.googleblog.com
Model-Based RL for Decentralized Multi-agent Navigation
2)arxiv.org
Model-based Reinforcement Learning for Decentralized Multiagent Rendezvous

